

When Words Aren’t Enough: How World Models Give AI a Richer Grip on Reality
Why the next leap in AI means thinking in worlds, not just text

The Limits of Language
When I was at Stanford, Fei-Fei Li’s lab was one of the most sought-after in vision AI. She and her students were pioneering the use of large-scale datasets to give models a richer, more grounded understanding of the world. That work showed me early on that data isn’t just fuel—it’s the bridge between abstract algorithms and real-world perception.
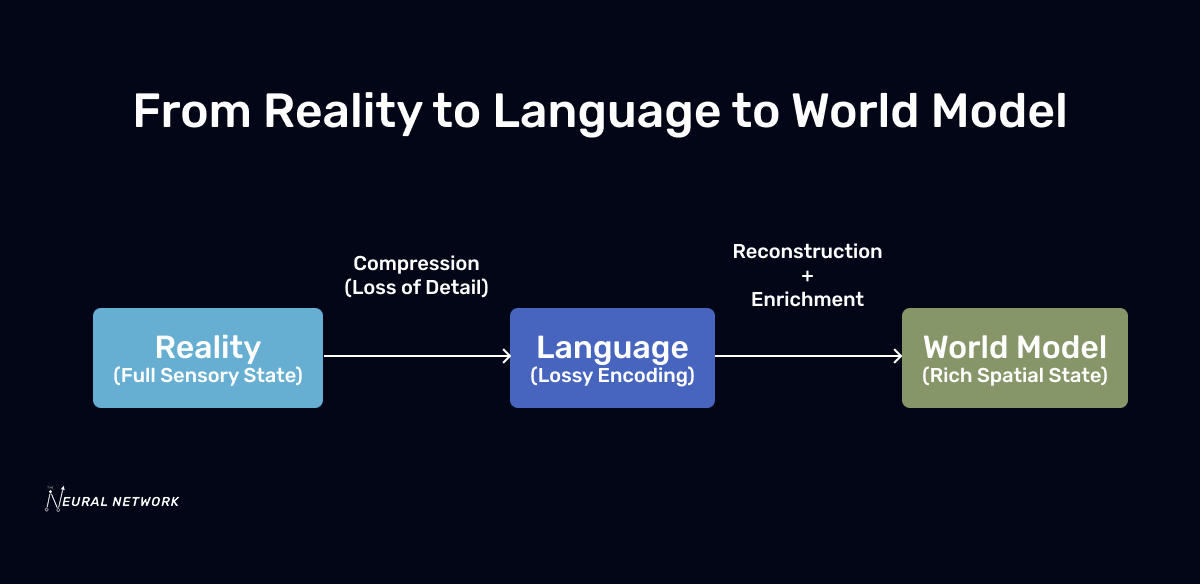
Language is one of humanity’s most remarkable inventions, bridging the conceptual and physical worlds. It lets us share ideas, coordinate across distances, and preserve knowledge. But it is also an imperfect, lossy compression of reality.
Say, “A red ball rolled across the table.” You picture the scene—but the actual state is far richer. The ball’s precise weight, spin, and speed; the table’s exact surface friction and position; the shifting pattern of shadows—all of it disappears in the compression into words.
Humans don’t notice because we bring a lifetime of shared, implicit knowledge to fill the gaps. AI models trained purely on text don’t have that luxury. Their reasoning is limited by the bandwidth of language.
That’s where world models come in. Instead of reasoning only from symbolic descriptions, they maintain a rich, spatially grounded, temporally coherent representation of the environment—whether physical or virtual. Think of it as an internal canvas that preserves the details language leaves out.
What is a World Model?

A world model is a learned internal representation that predicts how the environment changes over time and under different actions. It merges perception, memory, and prediction into a single latent space.
A world model is an internal representation that predicts how an environment changes over time and in response to actions. It blends perception, memory, and prediction into a single latent space.
Early work—like Ha & Schmidhuber’s World Models (2018) and the PlaNet and Dreamer series—proved an agent could learn latent dynamics directly from pixels and use “imagined rollouts” to plan its next move.
Today, models such as DreamerV3, OpenAI’s Sora, and Wayve’s GAIA-2 operate over multi-modal, 3D-aware scene representations, giving them far richer predictive power.
The key distinction: language is a symbolic snapshot; a world model is a continuous simulation.
Spatial Intelligence: The Antidote to Lossy Encoding
The reason world models matter is that they give AI spatial intelligence—the ability to reconstruct what language leaves out. A capable model can:
Infer 3D geometry and relationships from multiple viewpoints and sensors.
Maintain object permanence, tracking items even when they’re out of sight.
Predict physical interactions, such as whether stacked boxes will topple.
Anchor reasoning in egomotion and spatial memory, so it knows not just what it sees, but where it is in relation to everything else.
This closes the gap between what’s said and what’s true. If you tell it, “Put the mug back where it was,” a language-only model might not know the “where” without explicit coordinates. A world model can recall its last known 3D location.
Put another way: Language is a codec for communication. World models are a codec for reality.
Architecture of a Spatial World Model

A modern spatial world model has several key layers:
Representation Layer
NeRFs, Gaussian Splatting, and Bird’s-Eye-View (BEV) latents create dense, geometry-aware scene representations. These preserve spatial structure far beyond what text can describe.Object-Centric Backbone
Slot Attention and similar methods factor the scene into discrete entities with attributes and relationships, enabling compositional reasoning.Dynamics Model
Latent state-space architectures (Dreamer-style) predict how states evolve under actions, allowing the model to “imagine” future scenarios before acting.Learning Signals
Self-supervised video objectives and predictive training (e.g., JEPAs) teach the model to anticipate changes and respect physical constraints without labeled data.
In this architecture, language is an adapter layer—a way to query or update the rich latent state, not the core reasoning medium. A language instruction is parsed into this richer spatial state, where planning and reasoning occur.
The Language → World Model → Action Loop
The process typically unfolds as follows:
Language Input (lossy): Human provides an instruction, e.g., “stack the boxes in the corner.”
Language-to-State Adapter: Parses the instruction and grounds terms like “boxes” and “corner” in the current scene representation.
World Model Core: Maintains a multimodal, 3D state, including object positions and free space.
Simulation & Planning: Runs imagined trajectories to evaluate possible stacking sequences for stability.
State-to-Action Adapter: Converts the chosen plan into motor commands, code, or virtual events.
Perception Feedback: Updates the state using vision, depth, or tactile data, correcting for deviations.
By keeping perception in the loop, the model avoids drifting into purely symbolic reasoning and remains grounded in the physical or simulated reality it inhabits.
Applications Across Real and Virtual Worlds
In the physical world:
Robotics: Interprets vague instructions like “pick up the mug” by inferring shape, position, and how to grasp it safely.
Autonomous driving: Predicts how the road scene will evolve, from vehicle trajectories to pedestrian movement.
AR devices: Grounds ambiguous commands like “highlight that route” to specific visual elements in a user’s view.
In virtual environments:
Games: Generates coherent environments and NPC behaviors from incomplete scripts.
Digital twins: Models factories, supply chains, or city systems with spatial and temporal accuracy.
Bridging the two:
Domain randomization, embodied pretraining, and continual learning help models transfer what they’ve learned in simulation to the real world without catastrophic failure.
Strategic Implications and What’s Next
Relying solely on language locks AI into its inherent bottleneck. Pairing language with a world model unlocks a high-fidelity mental map that enables safer, more adaptable, and more general decision-making.
In this setup, language serves best as the interface layer, not the reasoning substrate—especially in high-stakes domains like autonomous fleets or surgical robotics, where every decision must be grounded in reality.
Over the next 12–24 months, expect this approach to accelerate:
Object-centric + 3DGS pipelines will become the default for spatial reasoning, combining semantic understanding with precise geometry.
Action-aware video world simulators will merge controllable dynamics with photorealistic rendering, narrowing the gap between generative models and deployed agents.
Shared scene/state schemas will allow multiple agents to collaborate on a single, unified representation of the world.
Benchmarks will evolve to measure physics and causal reasoning, moving beyond static perception tests toward evaluating true real-world competence.
Closing Thoughts
Language will remain the bridge between humans and machines—but it is not the world itself. By design, it strips away much of the spatial, physical, and causal richness needed for robust action.
World models restore that richness. They let AI think in full fidelity, simulate plausible futures, and act with precision in both physical and virtual domains. As these models advance—fusing object-centric reasoning, high-fidelity geometry, and action-aware simulation—they will move us closer to AI systems that can operate confidently in the messiness of the real world.
Language is for telling. World models are for knowing. The AI systems that matter most will be fluent in both—communicating in words when they interact with us, but thinking in worlds when they act for us.