

What’s the hype with model distillation?
Making high-performance models practical for real-world applications

Lot’s has been happening in the AI space recently. DeepSeek’s R1 model release and OpenAI’s new Deep Research product are reshaping the landscape for AI and they’re redefining the cost and accessibility of powerful reasoning models.
But there's a catch that rarely makes the headlines: these models are absolutely massive. We're talking "needs a data center to run" massive.
One of the ongoing challenges with AI is making them usable and practical for real-world applications. The main issue is that as AI models have continued to grow increasingly powerful, their resource-intensive nature has created a barrier to widespread adoption.
We have to think broader than browser-based chat interfaces. Although useful and entertaining, the real problem is deploying these powerful models and getting utility from them in products that have human touchpoints.
We’re living in a world where AI capabilities are exploding, but deploying them often feels like trying to fit an elephant through a keyhole.
Distillation, a groundbreaking approach to model compression, has emerged as a key component in bridging this gap. By enabling the transfer of knowledge from large, complex models to smaller, more efficient ones while maintaining comparable performance, distillation is enabling a much broader range of applications for AI.
Understanding the Mechanics of Model Distillation
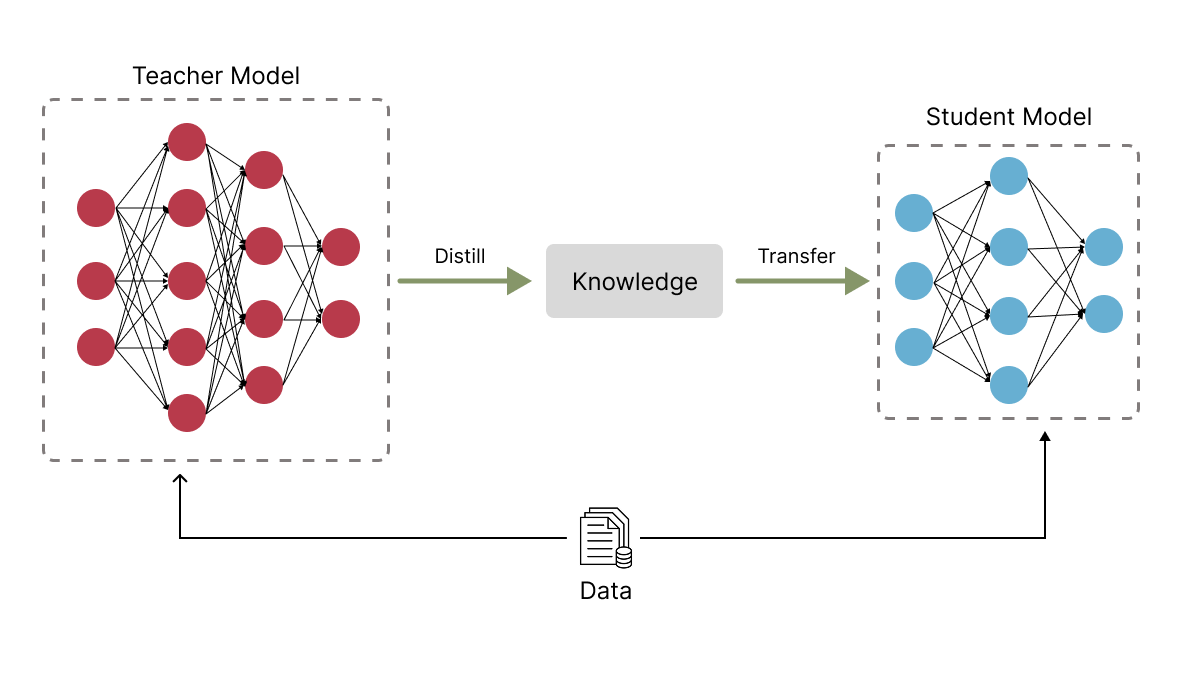
Model or knowledge distillation is a technique where a smaller (think: less parameters)—referred to as the “student”—learns from a larger, more complex model (think: more parameters), known as the “teacher.” What this means is that the student model is not just copying the final decision outputs (hard labels) or the teacher, instead the student actually learns from the soft output distributions (soft labels) provided by the teacher.
Think about it like learning your times tables. Sure you could just memorize the correct answers, but this falls apart very quickly. If you learn and understand what’s happening with multiplication, then you can generalize that process to any combination of numbers.
At its core, model distillation involves four steps:
Training a large teacher model
Generating soft labels
Training a smaller student model
Optimization and fine-tuning
This process allows AI models to become smaller, faster, and more efficient, making them viable for real-world applications without sacrificing too much accuracy.
Training a large teacher model
A teacher model is something you’re already familiar with. It’s just a high-capacity model (e.g., o1, R1, 3.5 Sonnet) that’s been trained on a large dataset. These models have high accuracy, but have substantial computational and memory requirements, often making them impractical for direct deployment.
In the context of distillation, one of these models serves as the primary source of knowledge. It will be used to “teach” the distilled model.
Generating soft labels
Once the teacher model has been trained, we use it to produce probability distributions (soft labels) over possible outputs.
Soft labels were a crucial innovation in figuring out distillation. Unlike traditional hard labels, which produce binary or one-hot encoded classifications (1 for correct, 0 for others), soft labels provide richer information than just a single correct answer by utilizing probabilities.
For example, when classifying an image of a cat:
Hard label: "Cat" → [1, 0, 0, 0] (Only "Cat" is correct)
Soft label: "Cat" → [0.85, 0.10, 0.03, 0.02] (Other classes still get some probability)
The use of soft labels reflects the teacher model’s understanding of subtle relationships between categories (e.g., “Cat” as 85%, “Dog” as 10%, “Rabbit” as 3%, “Mouse” as 2%).
This richer information helps the student model learn not just the correct answers, but also the underlying patterns and relationships in the data.
Training a smaller student model
The student model is trained using two types of information from the teacher model.
Soft labels: Generated in the previous step, these reflect the teacher model’s confidence in its predictions and the relationship between classes.
Hard labels: These are the traditional outputs from the teacher model that identify the correct class for an input.
Using a combination of traditional supervised learning and distillation techniques, the knowledge of the teacher model is distilled into the student model by training it to match the teacher model’s outputs.
I won’t go too deep into the weeds here, but essentially, during this process, we’re trying to achieve two objectives: minimizing standard loss and minimizing distillation loss.
Minimizing standard loss (cross-entropy loss)
The goal is to reduce the difference between the predicted probability distribution and the true distribution of the target labels. This ensures the student learns from the ground-truth hard labels provided by the teacher. This is akin to traditional supervised learning.
Minimizing distillation loss (Kullback-Leibler divergence)
In minimizing distillation loss, we’re specifically trying to minimize Kullback-Leibler (KL) divergence loss. The KL divergence measures the difference between the probability distributions of the teacher and student models.
There’s a lot more math behind this, but the aim is to minimize this loss to ensure that the student learns effectively from the teacher model’s outputs.
There’s a lot more to it, but during this training process, the student model can also learn from different knowledge categories of the teacher model. We’ve covered the soft labels, but there’s also intermediate layer features and the relationship between various layers and data points.
If you want a more in-depth explanation, this article gives a very detailed explanation: How to do knowledge distillation.
Optimization and fine-tuning
Once the initial training and knowledge distillation is complete, the student model undergoes various optimization and fine-tuning techniques to ensure it performs efficiently.
Weight pruning: Eliminates less important parameters, reducing the model size without significant performance degradation.
Quantization: Reducing the precision of numbers (e.g., converting 32-bit floating point numbers to 8-bit representations), significantly reducing memory requirements while maintaining an acceptable level of accuracy.
Low-rank factorization: Compressing the student model’s weight matrices, reducing the model’s overall size while maintaining performance.
Neural architecture search: Finding an optimal student model architecture, enabling more efficient learning from the teacher.
What advantages do distilled models provide?
Now that we’ve covered the technical process of model distillation, let’s circle back to why it matters for practical applications.
Increased computational efficiency: One of the primary benefits of distillation is the reduction in computational resources required for deploying a model.
Distilled models require less memory and processing power, making them suitable for deployment on resource-constrained devices like mobile phones and edge computing platforms.
Using smaller models leads to faster inference times and improved real-time performance.
Cost reduction: Smaller models consume less energy and can run on less expensive hardware, resulting in lower operational expenses.
Instead of paying thousands or even millions in cloud computing costs, you might be able to run your AI workloads on standard hardware.
This makes AI solutions more scalable and accessible to a wider range of businesses.
Adaptability and data efficiency: Distilled models not only maintain comparable performance levels to their larger counterparts, but can also be efficiently fine-tuned for specific domain applications without full re-training.
This data-centric approach maximizes the utility of data that’s already available—lowering costs and accelerating time-to-market.
Real-World Applications and Impact
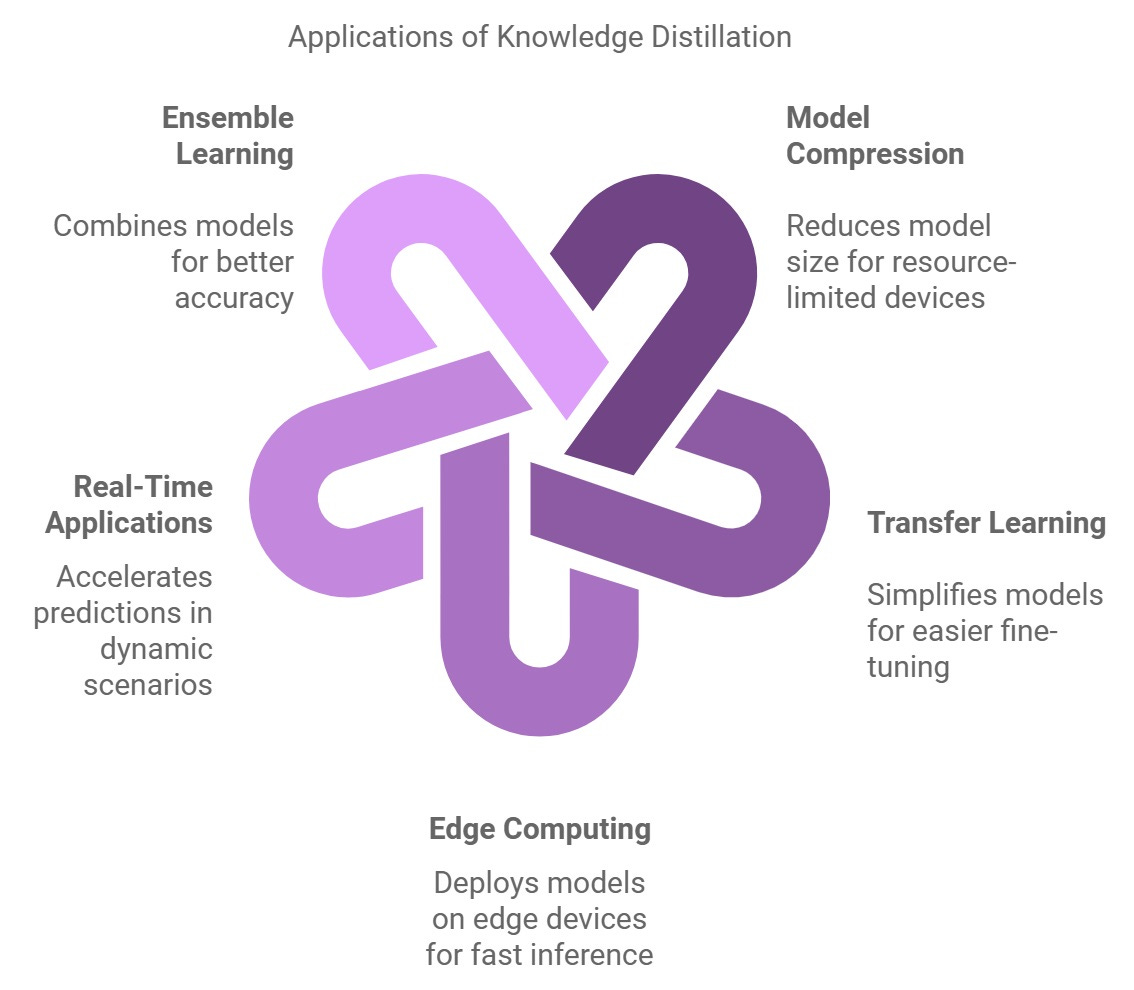
Model distillation has far-reaching applications across multiple industries:
Edge Computing and IoT: You can now put sophisticated AI capabilities directly into smart cameras, IoT sensors or wearables.
Think: “smart camera that can detect quality control issues in real-time” instead of “send everything to the cloud and wait.”
Healthcare: Portable diagnostic tools like handheld ultrasound machines can process complex data rapidly and locally.
Distilled models, such as HuatuoGPT, have demonstrated the ability to outperform their teacher models in specialized tasks while being significantly smaller, allowing for improved accessibility and efficiency in medical applications.
Mobile Applications: Virtual assistants, chatbots, and image recognition tools benefit from distillation by reducing reliance on cloud computing, enhancing responsiveness and efficiency on smartphones.
Autonomous Systems: Drones, robots, and self-driving vehicles require real-time decision-making capabilities. Distilled models process vast amounts of data efficiently, ensuring fast and reliable decision-making.
Business Implications and Strategic Considerations
For business leaders and product managers, here’s what you need to consider when it comes to model distillation:
Cost reduction and resource optimization
Lower operational costs due to reduced computational requirements for running distilled models
Decreased energy consumption, leading to lower electricity bills and improved sustainability
AI solutions can be deployed on less expensive hardware, making advanced AI more accessible to smaller businesses and startups
Enhanced performance and resource optimization
Faster response times and improved real-time processing capabilities, crucial for applications like autonomous vehicles and virtual assistants
Better user experience in AI-powered applications due to more responsive and fluid interactions
Improved scalability, allowing businesses to serve more users without compromising performance
Market opportunities and competitive odvantage
Startups and smaller businesses can deploy AI-powered solutions without the need for high-end hardware, leveling the competitive landscape
Potential for rapid innovation in fields such as healthcare, education, and financial services
Being able to run AI models locally isn’t just about cost, it’s about creating new categories of products that weren’t possible before
Future Prospects and Challenges
As AI continues to evolve, model distillation techniques are expected to become even more sophisticated. Ongoing research is exploring novel distillation methods, enhanced optimization strategies, and broader applications in privacy-preserving computation and edge AI.
However, several challenges remain:
Balancing performance and size: While model distillation significantly reduces resource requirements, achieving optimal performance with smaller models remains an ongoing challenge.
Adapting to new architectures: The rapid advancement of AI requires distillation techniques to evolve continuously to accommodate emerging model architectures.
Competitive differentiation: As AI models become more commoditized, businesses must find innovative ways to differentiate their offerings beyond raw performance metrics.
Final Thoughts
Model distillation is going to serve as a vital bridge between the theoretical capabilities of advanced AI and its practical real-world implementation. By enabling the creation of smaller, more efficient models that maintain high performance, distillation is democratizing AI technology and unlocking new possibilities across industries.
We’re still in the early days of this technology, but the direction is clear. The future of AI isn’t just about building bigger models, it’s about making them practical and deployable in real-world business contexts.
Remember: The most sophisticated AI model in the world doesn’t help your business if you can’t actually deploy it.
As AI becomes increasingly commoditized, organizations must focus on innovative applications and domain-specific optimizations to maintain a competitive advantage. The companies that understand this and act on it now are going to have a significant advantage in the next phase of the AI revolution.