

What do VLMs and ASICs have in common?
The parallel journeys of AI models and the chips that power them

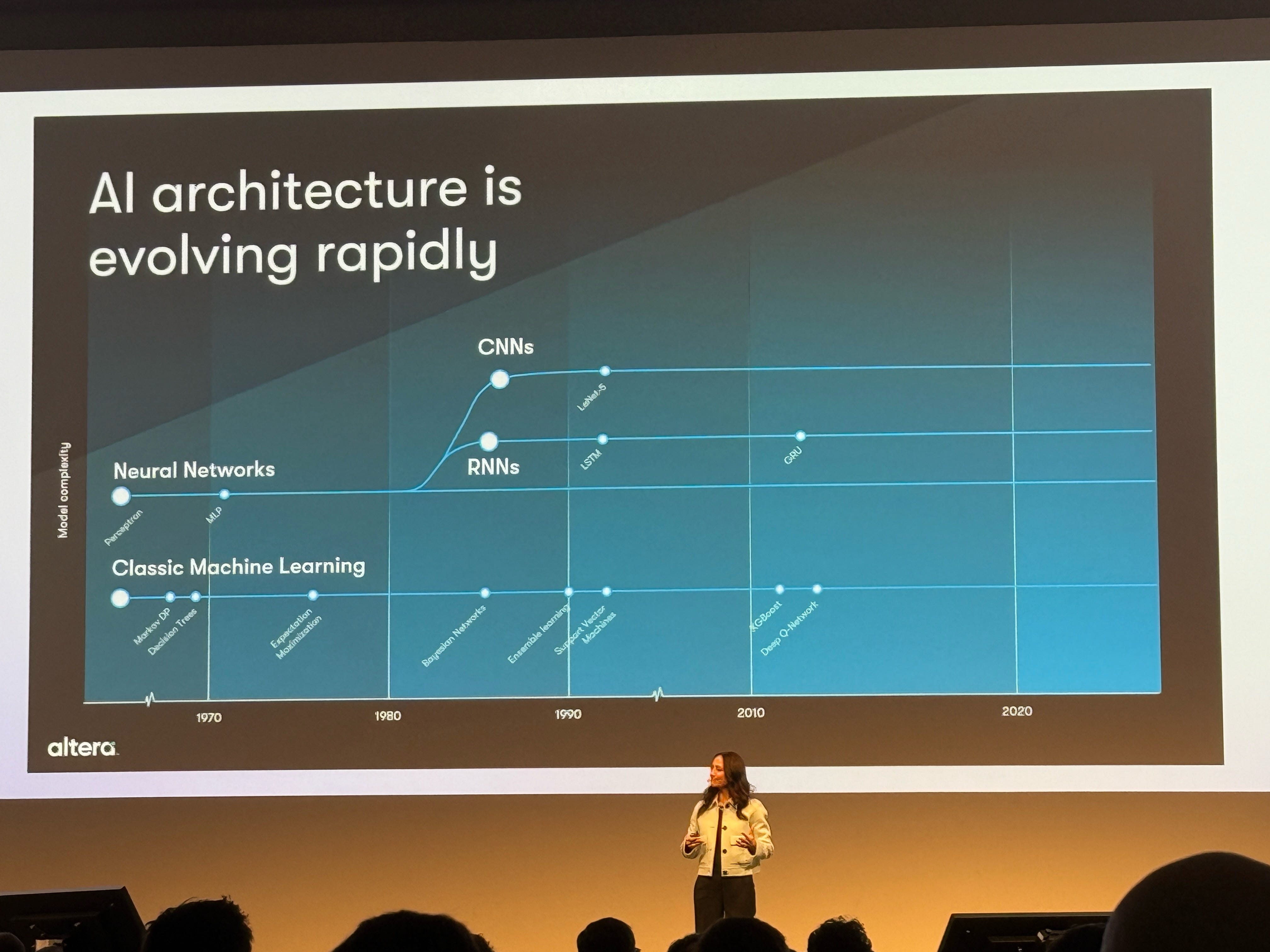
In the world of technology, we often see similar evolutionary patterns play out across different domains. Today, I'm going to walk you through one of the more interesting parallels that's largely escaped mainstream attention: how Vision-Language Models (VLMs) and specialized AI silicon have followed remarkably similar maturation curves.
Both stories begin with flexibility prioritized over efficiency and end with the exact opposite trade-off. Both involve billions of dollars of investment. And both have significant implications for where computing is headed next.
The Edge-ward March of VLMs
VLMs began their life as massive, cloud-dependent beasts. Early models like CLIP and Flamingo were revolutionary in their ability to understand both images and text, but they demanded substantial computational resources that confined them to data centers.
What we've witnessed since then is a relentless push toward the edge. We’re in the midst of a big paradigm shift from what I call “Edge 1.0” to “Edge 2.0”.
Edge AI 1.0 was characterized by task-specific compressed models, each trained on different datasets for narrow applications. It was functional but inefficient—like having a different specialized tool for each home repair job instead of a well-designed multi-tool.
Edge AI 2.0 has introduced versatile foundational VLMs that can adapt to numerous scenarios with remarkable flexibility. These models aren't just smaller; they're fundamentally redesigned for efficiency without sacrificing their core capabilities.
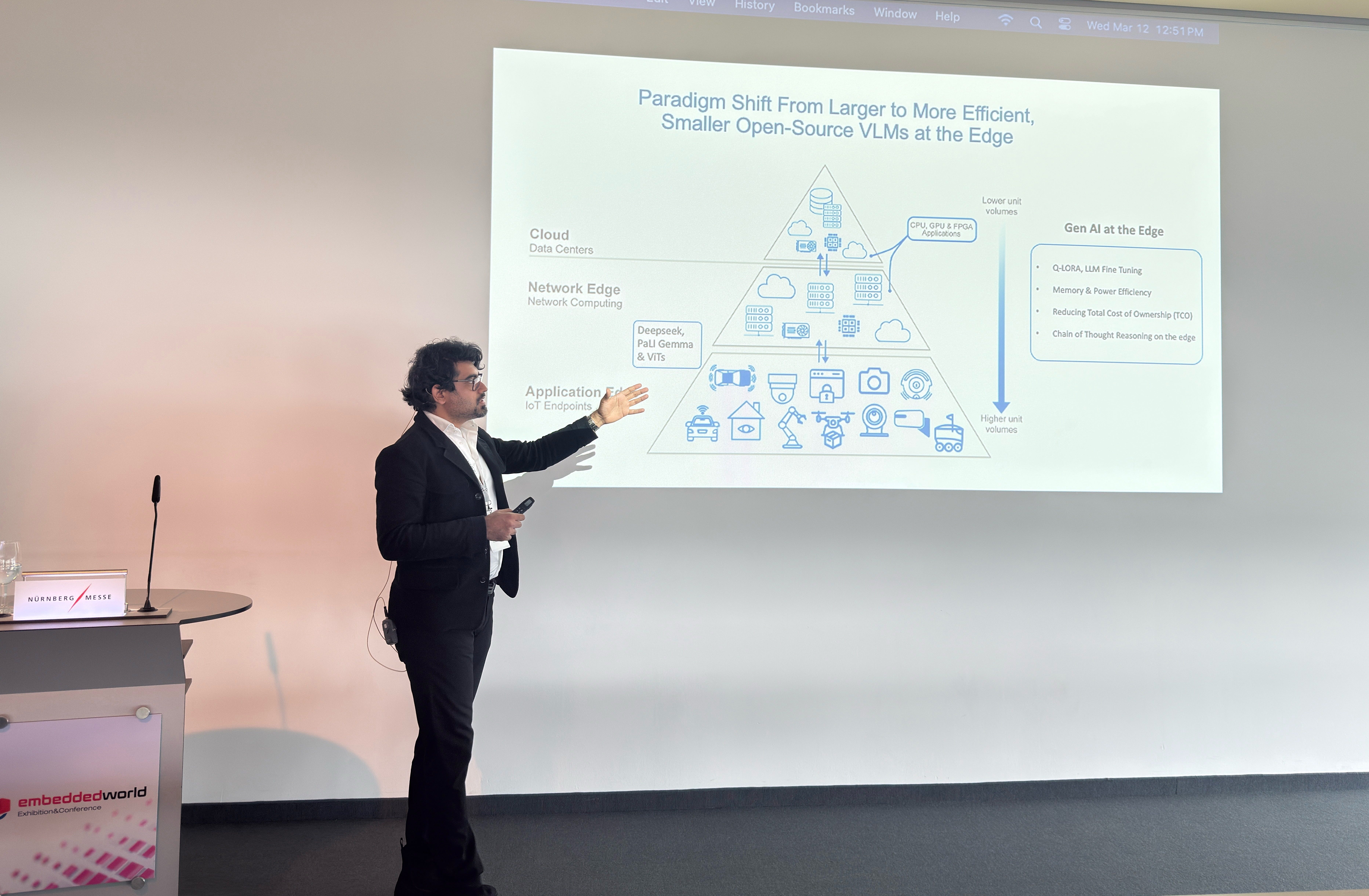
This shift has been made possible by a number of innovative compression and techniques that dramatically reduce model footprint while preserving performance like:
Quantization (particularly Activation-Aware Weight Quantization or AWQ)
Pruning (structured and unstructured)
Distillation
Other advanced compression methods (ClusComp and low-rank approximation)
Big leaps have also been made with fine-tuning methods which are critical when adapting large-scale VLMs to downstream tasks with limited computational budgets.
Fine-tuning with prompts and adapter-based fine-tuning have been extremely popular methods, as of late, due to their effectiveness in alleviating the resource burden related to retraining and full fine-tuning of large models.
But even with these advances, practical deployment remains challenging. Models like GPT-3 with its 175 billion parameters would require about 350GB just for inference memory, while even relatively modest VLMs like CLIP (63 million parameters) strain the capabilities of edge devices with their typical 1,000-5,000 mAh energy capacity.
When FPGAs Gave Way to ASICs
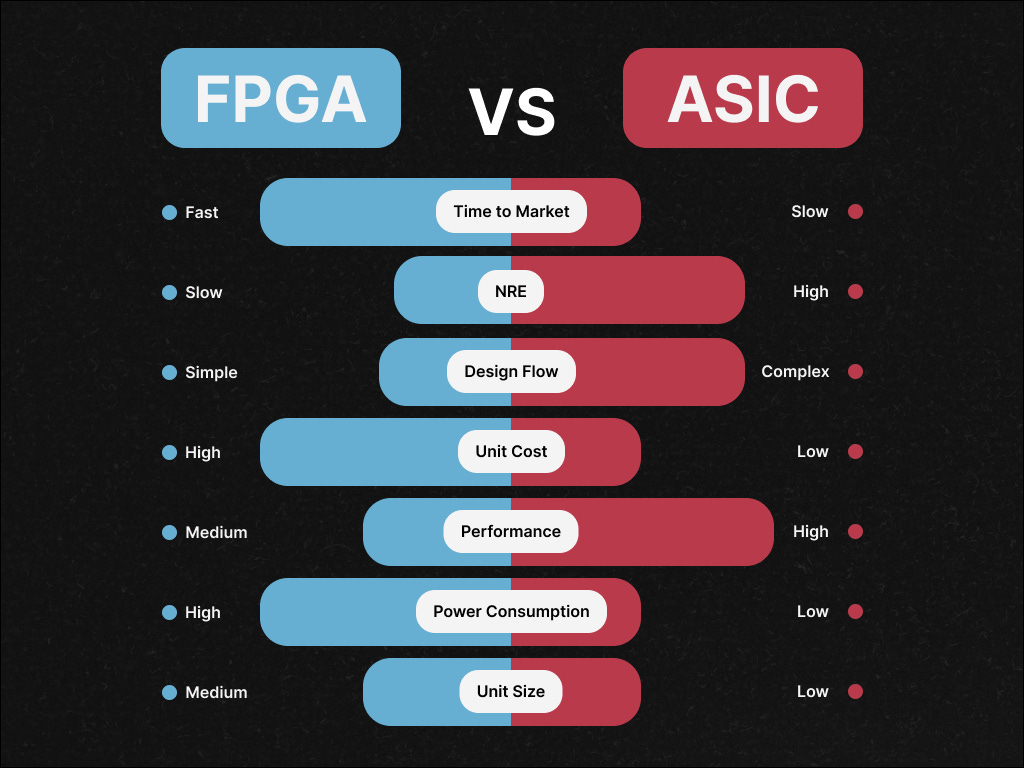
A similar evolution has unfolded in silicon. Field-Programmable Gate Arrays (FPGAs) initially played a crucial role in AI deployment, offering a unique value proposition: hardware flexibility after manufacturing.
Unlike CPUs (general-purpose) or GPUs (parallel-compute optimized), FPGAs could be reprogrammed to accelerate specific neural network architectures as the field was rapidly evolving.
Their customizability made them ideal for prototyping AI pipelines, while their deterministic performance provided ultra-low-latency inference for applications like autonomous driving and video processing.
But as AI workloads standardized—particularly transformer-based models and CNN-based vision systems—the market inevitably shifted toward Application-Specific Integrated Circuits (ASICs) purpose-built for AI tasks.
These non-reprogrammable chips trade flexibility for dramatic improvements in speed, power efficiency, and throughput. They've enabled the rise of edge AI by providing better power/performance balance, dedicated AI logic for common workloads, and cost efficiency at scale.

Intel's recent decision to sell a 51% stake in Altera to Silver Lake Partners for $4.46 billion illuminates this transition. The valuation of $8.75 billion is strikingly lower than the $16.7 billion Intel paid in 2015—a clear indicator of how market perceptions of FPGA's strategic importance have evolved.
Intel's Altera acquisition simply didn't deliver as expected.
The company had read the market too aggressively for FPGA acceleration in the datacenter, then failed to move decisively enough against rival Xilinx (later acquired by AMD). The planned transition of Altera's manufacturing from TSMC to Intel's own fabs proved costly and eroded market share.
By classifying FPGAs as "non-core" to their business, Intel has explicitly prioritized its resources toward its foundry operations and core product groups. The transaction structure—keeping a 49% stake—suggests Intel still sees value in keeping Altera as a customer for its chip manufacturing operations.
The Parallel Paths of Models and Silicon
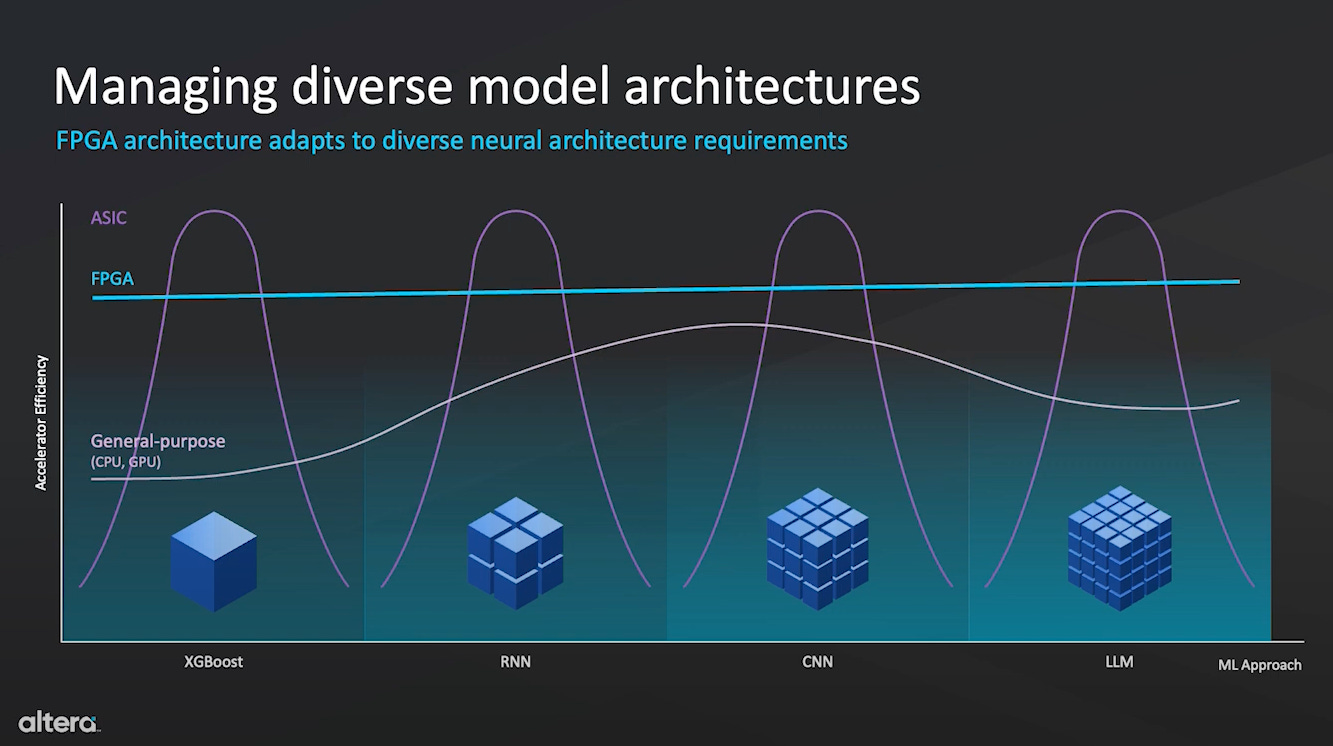
The evolution of both VLMs and AI hardware represents a maturation process where specialization eventually trumps flexibility once technological paradigms stabilize.
In both cases, the development process follows a roughly similar pattern:
For hardware:
Prototype on FPGAs
Test workloads
Crystallize the designs into ASICs
For VLMs:
Train foundation models
Profile performance bottlenecks
Specialize for deployment
What’s particularly interesting is that we're also seeing a bifurcation of markets in both domains.
Cloud providers still use FPGAs for rapid development and flexibility (Microsoft Azure is particularly fond of them), while hyperscalers deploy custom AI ASICs for production workloads.
Similarly, we maintain massive cloud-based VLMs for general-purpose tasks while developing highly optimized edge VLMs for specific applications.
The result is a tiered ecosystem where different technologies serve different niches based on their economic sense—not unlike how we still use both screwdrivers and power drills depending on the job at hand.
What This Means For The Future
The parallel evolution of VLMs and AI silicon isn't merely an interesting observation—it's a roadmap for how AI technology matures from experimental flexibility toward deployment-optimized efficiency.
1. Edge computing will drive unprecedented hardware specialization.
As VLMs continue their edge-ward migration, we'll see accelerated development of purpose-built silicon, creating a virtuous cycle of co-evolution between models and chips.
Success in this landscape won't go to those with the most flexible technologies, but to those who deptly balance performance demands against real-world resource constraints.
2. Strategic focus beats technological breadth.
Intel's partial divestiture of Altera represents a calculated recognition of where computing value will accumulate. By streamlining their portfolio to concentrate on more strategic assets, they're betting on specialization over diversification in the AI-driven computing landscape.
3. Flexibility matters during exploration, but ruthless specialization wins in deployment.
As the AI industry continues to mature, expect to see more companies making similar transitions—shedding the flexible tools that helped them explore in favor of the specialized tools that help them execute.
4. Adaptation beats raw capability
Much like evolution in nature, technology evolution doesn't favor the most powerful or the most flexible—it favors the most adapted to their environment. And in today's computing environment, specialized is increasingly beating flexible across both silicon and software.