

Why More Memory Won’t Fix AI Infrastructure
Nearly every AI infrastructure discussion eventually converges on the same phrase: memory shortage

Prices are rising, lead times are stretching, and product roadmaps are slipping. From a distance, the explanation seems obvious—we simply don’t have enough memory to keep up with demand. That framing is appealing because it reduces a complex situation to a single variable. It is also misleading.
What the industry broadly labels a memory shortage is not one constraint acting uniformly across the system. It is a stacked set of bottlenecks—allocation power, platform qualification, and bandwidth physics—that bind independently and often at different moments.
When those are collapsed into a single problem, forecasts break down, mitigation strategies underperform, and downstream disruptions appear sudden when they are anything but. The issue is not scarcity alone; it is misdiagnosis.
Scarcity Is Layered, Not Singular
If memory tightness were a conventional supply problem, the system would behave predictably. Capacity additions would ease pressure, prices would normalize, lead times would shorten, and product plans would stabilize over time. That assumption underpins much of the industry’s thinking.
But it is not what we observe in practice.
Instead, outcomes diverge. Some teams ship on schedule while others are forced into late redesigns. Some platforms move cleanly through generational transitions, while others miss them entirely.
These are not the symptoms of a single constraint gradually relaxing. They reflect a layered system in which different limits bind for different participants.
In practice, three constraints dominate. Allocation determines who gets memory and when. Qualification determines which platforms that memory can actually be used on. Bandwidth determines how efficiently data can be moved once it is there.
Each can become the limiting factor on its own, and increasing capacity only helps when all three align—which they often do not.
Allocation Comes First
The first bottleneck is not technical. It is economic.
Large AI data centers do not merely consume memory; they reshape its availability. Their purchasing power, early commitments, and tolerance for platform-specific coupling effectively reallocate supply across the ecosystem.
As inference-led demand accelerates, memory flows toward buyers that can absorb risk and lock in priority well ahead of product cycles.
The downstream consequences are easy to underestimate because they rarely show up cleanly. Smaller players do not just pay more. They receive parts later, freeze designs earlier than planned, or are forced into redesigns after assumptions break.
In many cases, the cost appears not as a higher bill of materials, but as a missed launch window.
This is why memory tightness increasingly manifests as architectural disruption rather than headline pricing. Allocation pressure propagates through planning and execution long before it reaches the P&L.
Adding capacity alone does not resolve this, because allocation is about priority, not volume.
Qualification Breaks Commodity Logic
Even when memory is available in principle, another constraint often binds before it can be used: qualification.
High-end AI memory—particularly HBM—does not behave like a fungible commodity. It is tightly coupled to specific platforms, and each accelerator generation introduces narrow qualification windows that must be met precisely.
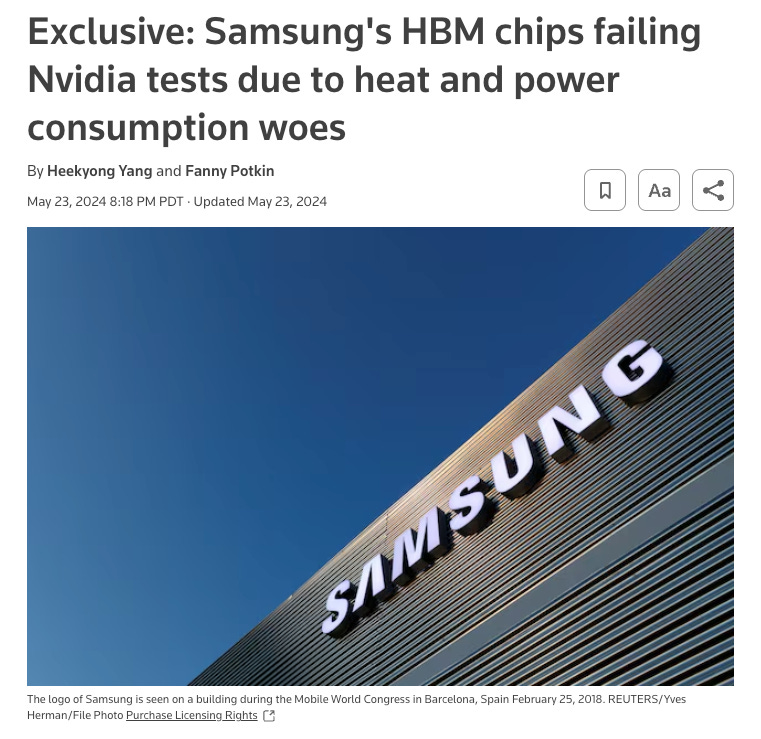
Miss the window, and that supply may as well not exist for that platform.
The result is a wave-and-reset dynamic. Supply ramps, platforms qualify, products ship, and then the generation turns. Outcomes depend less on aggregate availability than on execution across transitions.
Teams with qualification continuity move forward with relatively little friction. Teams that assume smooth handoffs discover that continuity is the exception, not the rule.
This is where linear forecasting consistently fails. It assumes gradual improvement where discontinuity is structural.
Capacity helps only if it arrives qualified, on time, and on platform. Otherwise, it simply pools elsewhere in the system.
Bandwidth Is Now the Physics Constraint
Even when memory is allocated and qualified, performance is no longer governed primarily by how much memory fits on a board. Increasingly, it is governed by how fast data can be moved.
Inference has shifted the physics. Decoder-heavy workloads stress memory not by storing large models, but by sustaining token throughput, moving KV caches, and meeting tight latency targets.
In these regimes, performance per dollar is constrained by bandwidth and data movement rather than raw capacity.
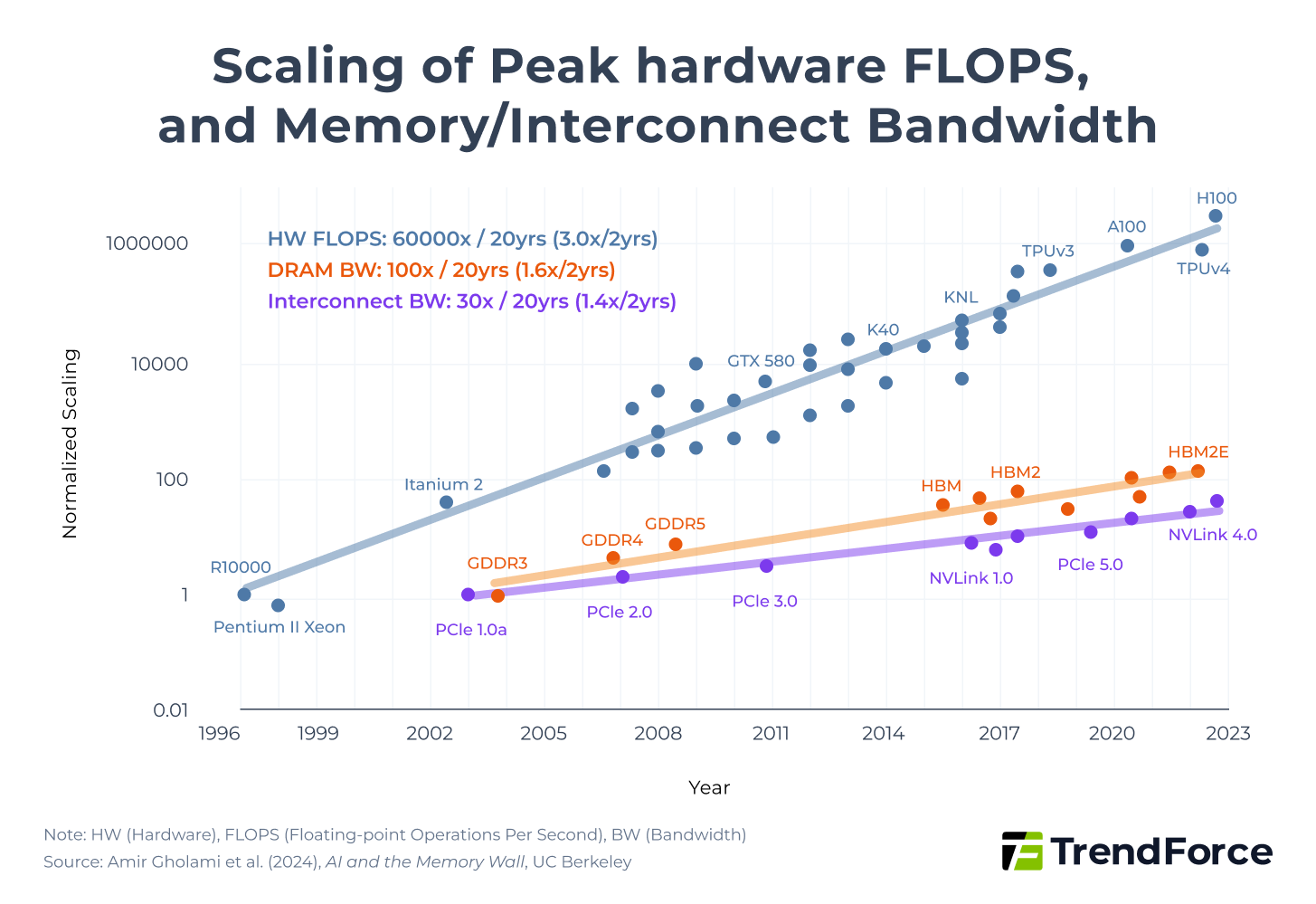
This is why inference-heavy systems often appear memory-bound even when capacity looks sufficient on paper. The constraint has migrated up the hierarchy—from storage, to interconnects, to on-package bandwidth.
Architectural responses such as pooling, tiering, and compression help, but they rarely eliminate the bottleneck. More often, they relocate it, exposing pressure at the next layer.
The Efficiency Trap
At this point, a familiar counterargument appears. If memory is tight, the system will simply become more efficient.
Smaller models, better compression, smarter caching—each reduces per-workload memory requirements, and all are real advances.
The problem is not that efficiency fails locally. It is that its system-level effects are often misunderstood.
Efficiency improves cost, latency, and usability. Those gains expand adoption, unlock new use cases, and increase overall deployment. As a result, total demand often rises faster than supply can respond.
In practice, efficiency does not reliably relieve memory pressure at the system level. In many cases, it sustains it by expanding the total addressable market.
Efficiency remains valuable, but it is not a reliable relief valve.
Why Forecasts Keep Missing
When allocation, qualification, and bandwidth are considered together, the recurring pattern becomes clearer.
Outcomes are non-linear, and transitions matter more than trends. Small differences in timing or execution produce large divergences in results. Share reshuffles occur at platform boundaries, and bottlenecks migrate rather than disappear.
Smooth curves give way to step functions.
This is also why asking how much memory will exist in 18 months consistently disappoints. More informative questions focus on structure rather than volume.
Who will control allocation during the next transition? Which platforms will qualify cleanly? Where will the bandwidth bottleneck move next?
Those variables, more than raw capacity, determine outcomes.
Fault Lines to Watch
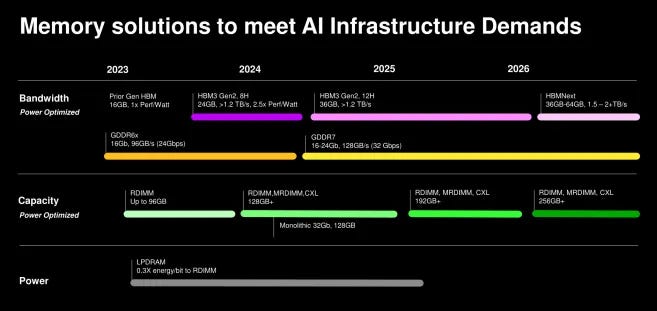
Several uncertainties remain unresolved.
It is not yet clear which constraint will dominate across all workloads. Allocation pressure varies by market, and while bandwidth dominates inference-heavy deployments, not every system is inference-bound.
Tiering may push bottlenecks into interconnects and storage faster than expected. Or it may flatten cost curves for specific application classes.
There is also a broader strategic question still in play: whether these dynamics represent a permanent break from prior cycles or a repeatedly discontinuous one.
If qualification continuity improves, volatility may soften. If it does not, resets will remain structural.
These questions are falsifiable. That is a strength.
What to Watch Next
If memory tightness were a single problem, the fix would already be clear. It is not, which is why the system continues to surprise even experienced participants.
The most useful signals will not come from headline capacity numbers. They will come from quieter indicators: qualification continuity across generations, the evolving economics of bandwidth in inference-heavy systems, and whether efficiency gains show up as margin relief or as expanded demand.
Until those forces align, memory shortage will remain a convenient label—and a weak guide to strategy.
The real constraint is not memory in isolation, but the system that governs how it is allocated, qualified, and used.