

Open-Source AI Gaining Momentum
How to setup open-source models like DeepSeek R1 on your local machine

There’s been a lot of buzz about DeepSeek over the last week. It’s hard to imagine any conversation around AI that doesn’t involve R1 in some capacity.
I’ll skip over telling you what DeepSeek R1 is. That being said, if you want an overview, I wrote an article you’ll probably like called: Is DeepSeek an OpenAI Killer?
One of the more concerning developments that’s been frequently overlooked is DeepSeek’s privacy policy. Basically, you don’t have any privacy. None.
It can collect almost any and all information from you and share it with almost anyone. Additionally, all of this information is collected and stored on servers located within China.

The solution? Run it locally.
What makes DeepSeek so cool is that it’s open source and you can easily download it on your own computer and use it without sending any data to anyone.
It only takes a few minutes to get it up and running, here’s how to do it.
The Tutorial
We’ll start with a free product called Ollama. There’s a lot more to it, but Ollama is basically an open-source tool that makes it easier to run LLMs on their own computers.
Ollama works for all operating systems, so regardless of what kind of device you have you’ll be able to use it. Just click the download button and install the app like you would normally do.
Next, we’re going to skip past the “Run your first model” window and open our terminal instead. I’m doing this on a Mac so it may look a bit different if you’re using Windows or Linux.
We’re going to run the following command:
ollama run deepseek-r1:14b
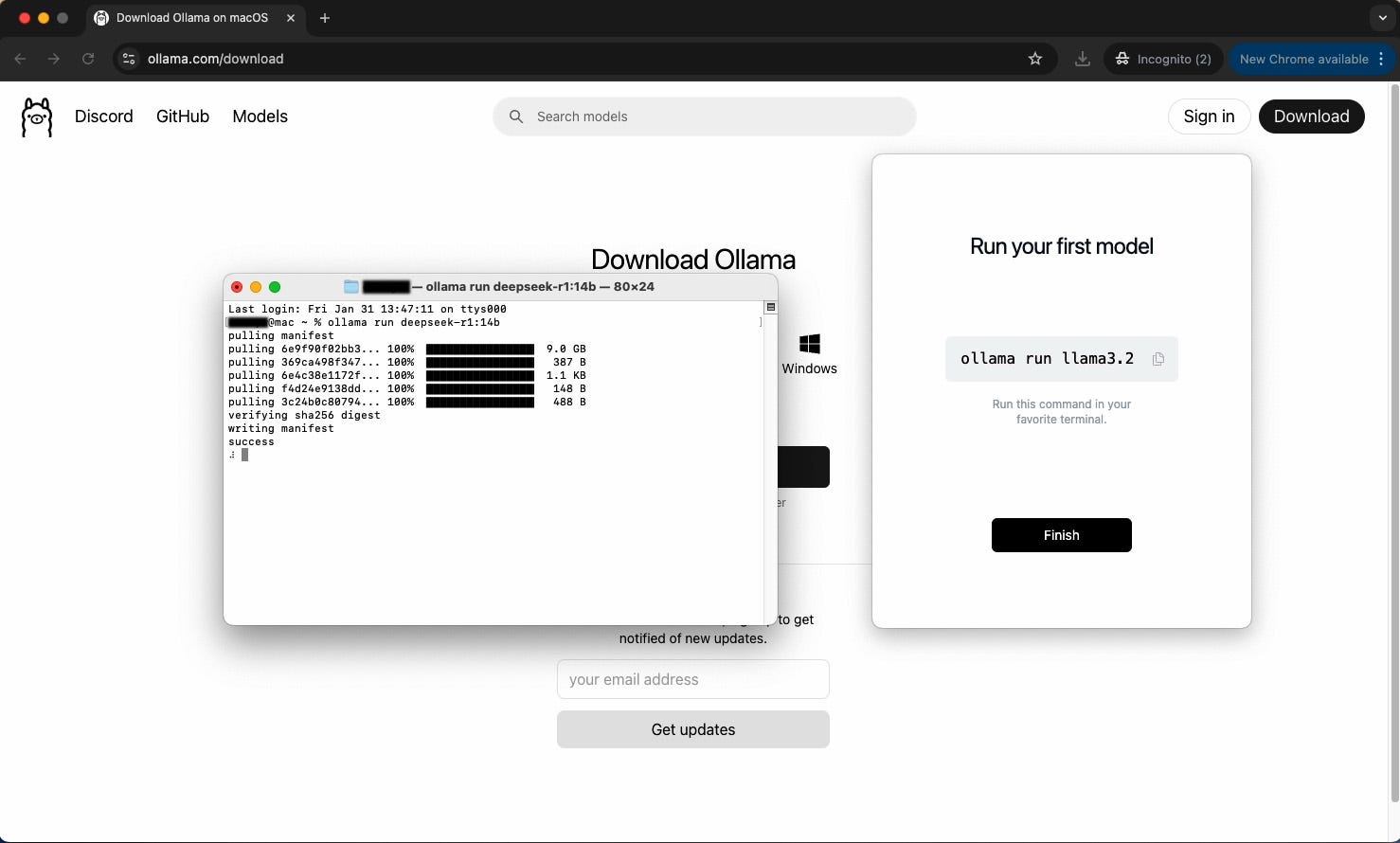
The model will take a few minutes to download since it’s about 9GB. If it downloaded successfully, your terminal should look like below:
If you get a “connection refused” error, enter in the following command into your terminal.
launchctl setenv OLLAMA_HOST "0.0.0.0"
// This just makes it so Ollama can connect with your device.Congratulations! You now have DeepSeek R1-14b locally available on your device. Your data is safe and does not ever leave your computer.
You can use the same terminal instance to ask it questions just like you would with ChatGPT. I asked R1 a short question just as an example:
Keep in mind, depending on the power of your computer, you might have to wait a little bit to get an answer, but I think this tradeoff is well worth any privacy concerns.
If you want something faster, you can try running a distilled version of the model (8b, 7b, etc.) with less parameters. The model performance should be roughly the same, but it will be much faster.
Bonus: Using ChatboxAI to get a “ChatGPT-esque” User Interface
Chatbox AI is a free tool (paid upgrade for more features) that gives you a ChatGPT style interface for querying R1. There are some other cool features that it provides, but I’ll let you explore that on your own time.
Download the software and follow your usual install process.
Once it’s downloaded, open the application and navigate to the settings page. From there, you’ll select the Ollama API.
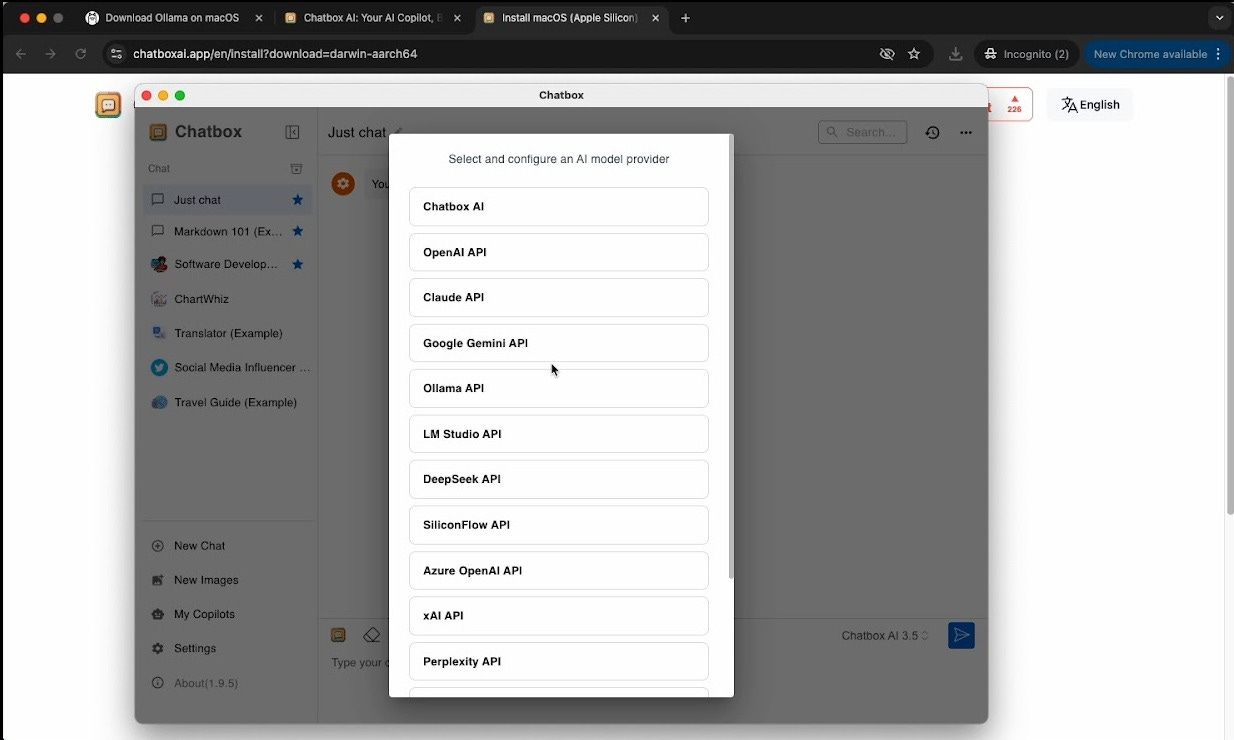
The following page should appear. Make sure you have Ollama open before doing this or else the “API Host” field won’t auto populate.
From there, select deepseek-r1:14b as your model. You can play around with the Context and Temperature settings to tailor the LLM responses to your liking.
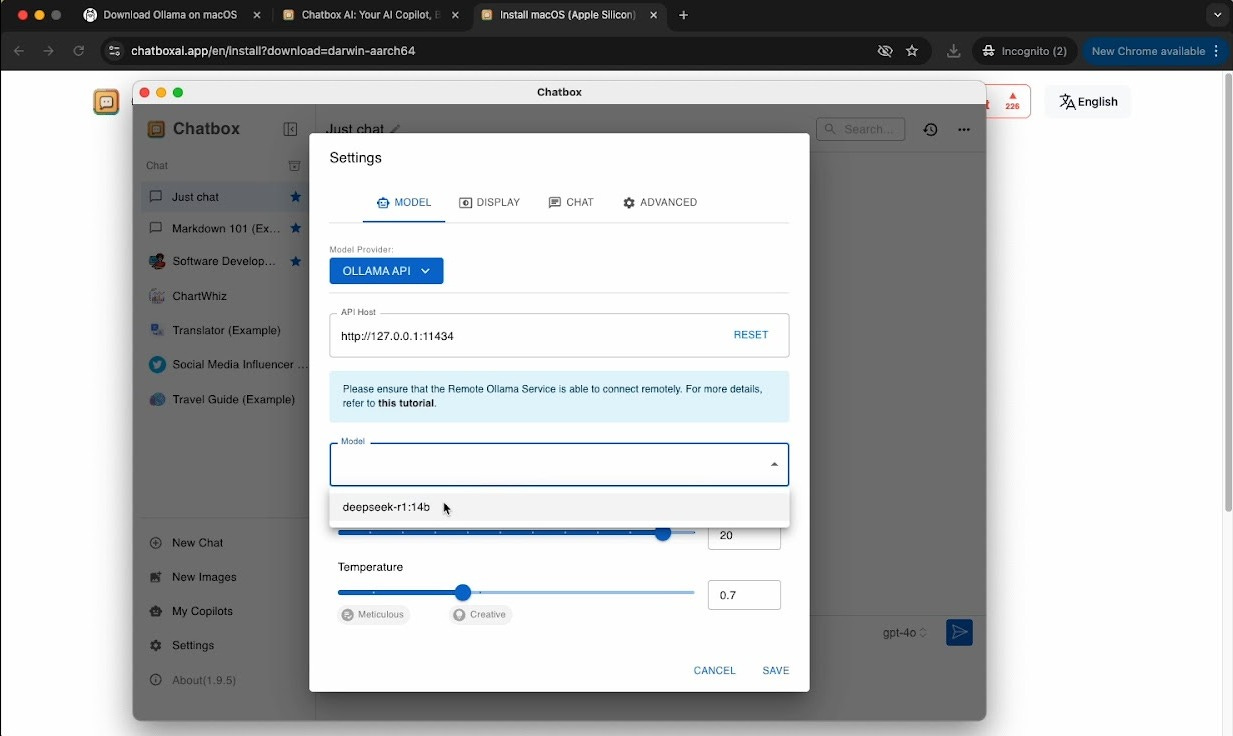
Going back to your Just Chat window, in the bottom right, you should see deepseek-r1:14b as the selected model. If not, just open the menu and select it from the list of available models.
Here’s a short clip of me using R1-14b in ChatboxAI:
A Quick Note on Response Times
As a reminder, when you're using LLMs through cloud services like ChatGPT, you're effectively borrowing time on specialized AI computing clusters.
These aren't your garden variety servers—we're talking about arrays of NVIDIA H100 GPUs, each carrying a sticker price of $25-30k. (Yes, that's thousand. No, that's not a typo.)
Now, you might be thinking "But I've got a top-of-the-line gaming rig with the latest NVIDIA card that cost more than my first car!"
Here's the brutal math: even that impressive consumer GPU is, optimistically, operating at perhaps a tenth of the computational capacity of a single H100. And remember, these clusters typically run multiple H100s in parallel.
This brings us to an important business consideration: when running these models locally, you're making a classic engineering tradeoff.
Yes, you'll see somewhat slower response times compared to cloud services. But in exchange, you maintain full data sovereignty and eliminate recurring compute costs.
For many business cases, particularly those involving sensitive data or specialized applications, this tradeoff is compelling, even if it requires setting appropriate expectations about performance.