

MedGemma is the Future of Healthcare AI
A compact, open foundation model that outperforms proprietary giants in clinical reasoning, imaging, and report generation

AI in healthcare has been long on promise and short on deployment. Until now.
Google’s MedGemma—a new suite of open medical vision-language models—isn’t just another research benchmark. It’s a practical, open-source toolset that outperforms many proprietary systems, especially in the high-stakes realm of clinical reasoning, medical imaging, and agent-based healthcare workflows.
We’ve seen AI transform industries like finance, logistics, and entertainment. But medicine has resisted (rightly) because precision matters and general-purpose models often fall short. With MedGemma, we’re seeing that change.
From Stanford Prototypes to Foundation Models
Years ago, I worked on a project at Stanford using classic ML to label chest X-rays. It felt ambitious, even if the results were limited. Around the same time, we ran a hospital proof-of-concept with Google Glass. Great idea, wrong decade.
Fast forward to today. Instead of hand-labeling data, we’re training multimodal transformers on 33 million image-text pairs. And instead of struggling with brittle models that break when conditions shift, we’re seeing robust, fine-tuned systems that hold their own against human experts. The pace of progress has been staggering.
What Is MedGemma?
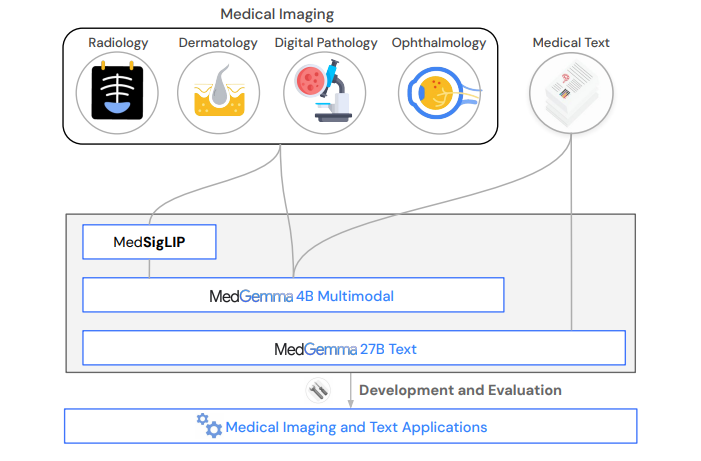
At a high level, MedGemma is built on top of Google’s Gemma 3 foundation models (4B and 27B variants) and extended with a medically tuned vision encoder called MedSigLIP. This combination allows it to perform joint reasoning across clinical images, patient notes, medical questions, and structured records.
The suite includes:
MedGemma 4B Multimodal – Lightweight, image+text model for rapid deployment
MedGemma 27B Text-Only – Optimized for long-form clinical reasoning and EHR interpretation
MedGemma 27B Multimodal – High-performance model for dense image+text inference
Technical Deep Dive: How to Build a Model That Thinks Like a Clinician
What makes MedGemma notable isn’t just performance—it’s how it was built.
Step 1: Train the Eye (MedSigLIP)
First, Google adapted SigLIP, their general-purpose vision model, using over 33 million medical image-text pairs. This included 635K examples from radiology, dermatology, and ophthalmology, plus 32.6M histopathology slides. Crucially, they retained a portion of the original WebLI training set to maintain general vision competence.
The result is MedSigLIP, a 400M parameter encoder that not only performs better on medical image classification than task-specific models but still handles natural images when needed. It’s lightweight, robust, and fully open.
Step 2: Connect the Eye to the Brain
With the visual side sorted, the team retrained Gemma 3 checkpoints using the new image-text pairs. To preserve general reasoning capabilities, medical data was weighted at just 10%. Enough to learn the language of medicine, but not enough to forget everything else.
Step 3: Fine-Tune the Behavior
Finally, the team used two stages of post-training:
Distillation: To kickstart its clinical reasoning, the team used distillation—training MedGemma on question-answer pairs originally generated by a much larger, more capable teacher model. It’s a shortcut to transfer expertise without brute-force retraining.
Reinforcement Learning: To sharpen its responses in multimodal settings, the team applied reinforcement learning—not just to boost accuracy, but to help the model generalize beyond the training set.
It turned out to be more effective than standard supervised tuning, especially for the edge cases that matter in clinical work.
Together, this created a model that not only understands clinical text and images—but reasons about them the way a human doctor would.
Benchmark Results
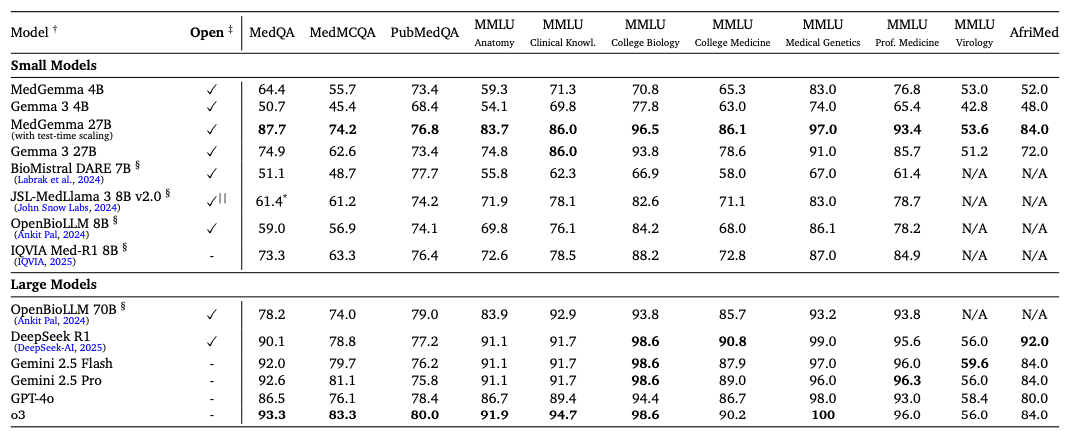
Across every key medical AI benchmark, MedGemma performs near the top—often beating much larger, closed-source models:
MedQA: 87.7% accuracy (MedGemma 27B), within reach of GPT-4-level systems.
MIMIC-CXR Classification: 88.9 macro F1, outperforming Gemini 2.5 Flash and Gemini 2.5 Pro.
Visual QA: Best-in-class zero-shot scores on SLAKE and VQA-RAD.
AgentClinic: 56.2% vs 54.0% human average—yes, it beat the doctors.
Radiology Report Generation: 30.3 RadGraph F1 after fine-tuning.
General Tasks: Strong performance on MMLU, MMMU, and PubMedQA shows it hasn’t lost generality.
Real-World Applications
What’s most exciting isn’t just the benchmarks—it’s the use cases:
Clinical Report Generation: MedGemma can draft imaging reports with 81% rated as equivalent to radiologist-written versions.
Pre-Visit Intake Agents: Automatically gathers and summarizes patient info before appointments.
EHR QA: Reinforcement-tuned model reduced error rates in synthetic EHR queries by nearly half (86.3% → 93.6%).
On-Device Triage Tools: With a 4B parameter option, MedGemma runs locally—no cloud API required.
Why Open Source Matters
Google’s decision to release MedGemma under an open license changes the game.
Hospitals can run the models on their own infrastructure. Startups can fine-tune them for niche domains. Researchers can build new applications without asking permission or paying API tolls. And critically, reproducibility and regulatory compliance are far easier with frozen weights than with opaque commercial endpoints.
Early adopters include DeepHealth (chest X-ray triage), Tap Health (clinical summarization), and Chang Gung Memorial Hospital (Chinese-language medical literature). The foundation is already spawning real-world tools.
Looking Ahead
MedGemma doesn’t replace doctors. But it does something almost as valuable: it makes expert reasoning more accessible, scalable, and composable. You don’t need to build an end-to-end system from scratch—you can start with a model that already understands medicine, then adapt it.
This is the shift we’ve been waiting for: from narrow, single-use models to true generalist platforms for clinical AI. As with the early days of ImageNet and BERT, the release of MedGemma is less about the current models than the ecosystem they’ll unlock.
Final Thoughts
When we started out building chest X-ray classifiers at Stanford, we had to fight for every percent of accuracy and hand-label thousands of samples. Today, MedGemma shows what’s possible when scale, compute, and medical context come together.
It’s not perfect. But it’s practical, performant, and—most importantly—open.
And in healthcare, that might make all the difference.