

Is DeepSeek an OpenAI Killer?
An open-source AI model that’s smarter than OpenAI’s latest $200 a month offering and it’s completely free with no usage limits.

Something fascinating happened in AI last week that’s going to cause a lot of Silicon Valley executives to lose sleep. A Chinese company just demonstrated that you can build a state-of-the-art AI model for less than what big tech spends on office snacks.
Let me explain why this matters.
The $6 Million (Allegedly) Model That Shouldn’t Exist
DeepSeek’s R1 model cost about $6 million to develop. That’s not a typo. For context, that’s less than one Meta AI executive’s annual compensation package. The conventional wisdom in Silicon Valley has been that building competitive AI models requires billions in capital, access to cutting edge Nvidia chips, and massive datasets.
The current narrative is that DeepSeek just proved that conventional wisdom wrong.
Followed by the kicker: they did it despite export controls that limit China’s access to advanced AI chips.

However, I’m still a bit of skeptic. The $6 million figure only accounts for the reinforcement learning training run and there were certainly more training runs that lead up to R1’s development.
DeepSeek is also backed and owned by High-Flyer, a Chinese hedge fund that manages billions in assets. Additionally, ScaleAI CEO Alexandr Wang claimed on live TV that “DeepSeek has about 50k H100s that they can’t obviously talk about due to the export controls the United States has in place.”
While we can’t say for sure how much access DeepSeek had to high-end chips, it’s important to note that R1 did not come to fruition in a vacuum. Developing it’s predecessors and assembling the talent required to produce such a groundbreaking model likely costed DeepSeek hundreds of millions of dollars.
Regardless of how the numbers ultimately shake out, the release of R1 is providing a counterpoint to the current capital requirements for developing AI models and the increasing commoditization of models themselves.
A New Paradigm in AI Training
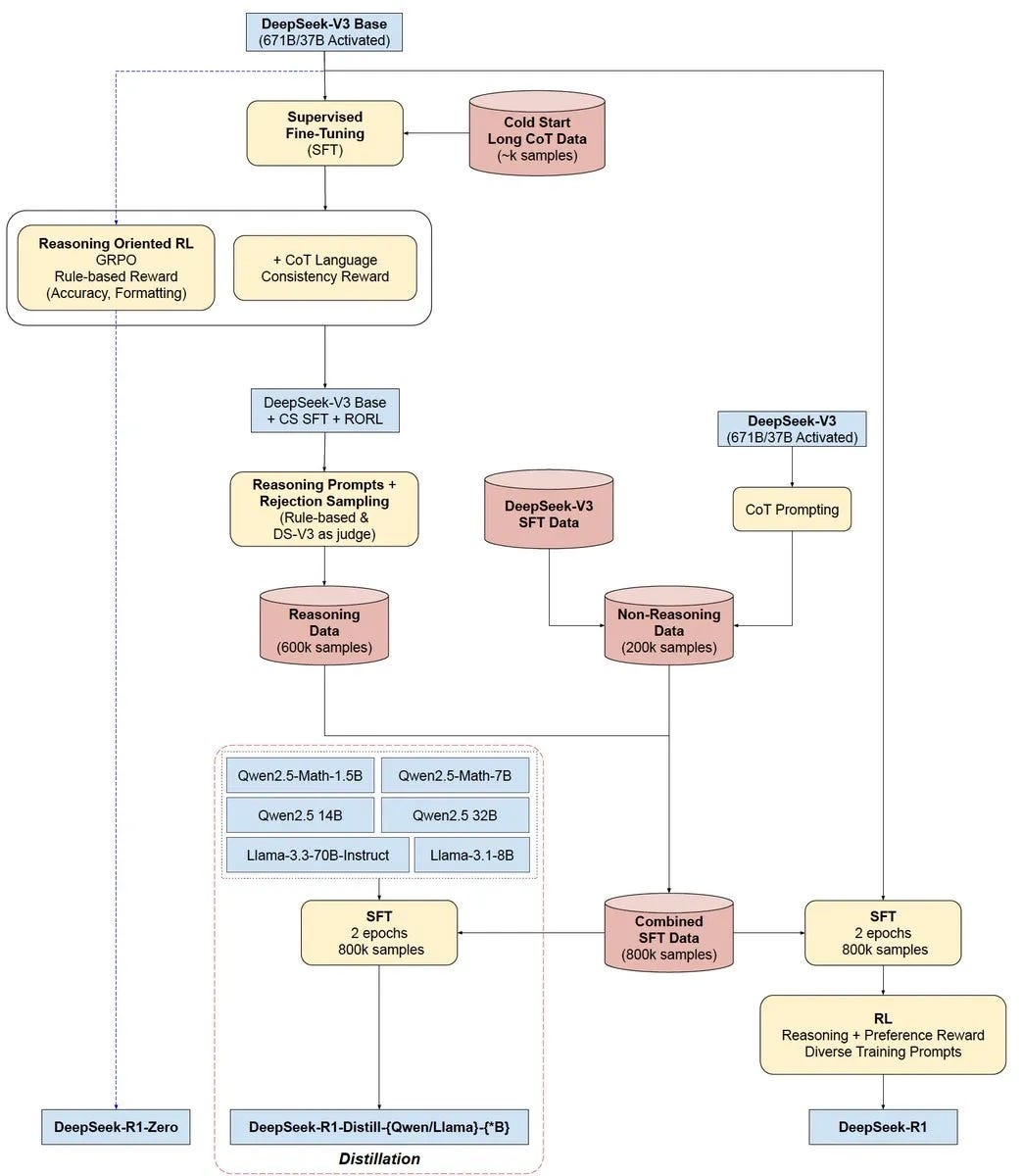
The contrast between traditional supervised fine-tuning (think: o1, Claude, LLaMa) and DeepSeek’s reinforcement learning approach illuminates a crucial evolution in AI development.
Most leading AI models today learn like honors students: they study carefully curated examples with step-by-step solutions. DeepSeek's R1 learns like a kid playing with Lego blocks: through trial and error, figuring out what works by doing.
This pure reinforcement learning approach isn't just different—it's dramatically more efficient. By learning in this manner, the model develops reasoning capabilities organically rather than through direct instruction. You don’t need massive datasets of perfectly labeled examples.
Think about the implications: you no longer need the vast data moats that companies like Google and Meta have built over decades.
This shift to reinforcement learning offers several advantages:
More Robust Problem Solving: The model can handle complex, unstructured tasks with greater adaptability.
Improved Generalization: It performs better on new and unseen scenarios, since it learns from first principles, rather than specific instructions.
Reduced Data Dependency: Less reliance on carefully curated and labeled datasets mitigates the bottleneck of data scarcity. Note: DeepSeek R1 was trained with 600k curated reasoning data samples, along with another 200k non-reasoning samples.
Efficiency Gains: Computational resources are utilized more effectively, enabling scalability even with hardware constraints.
The Test-Time Compute Revolution
As industry leaders, such as Ilya Sutskever, suggest that pre-training may be reaching its limits due to data scarcity, test-time compute has emerged as a promising pathway for advancing AI capabilities. Instead of focusing solely on resource-intensive training, this approach optimized computational efficiency during inference.
Test-time compute research is relatively affordable compared to pre-training, which requires extensive (and costly!) resources. With DeepSeek R1 emerging as a proof-of-concept, this research pathway is especially attractive for Chinese labs, especially without access to advanced AI chips.
DeepSeek’s implementation of test-time compute demonstrates several innovations:
Multi-Head Latent Attention (MLA): A novel architecture that reduces memory usage to just 5-13% of traditional models while maintaining performance.
DeepSeekMoESparse: A sparse model structure that activates only the components necessary for specific tasks, improving efficiency.
Selective Activation: Despite having 671 billion parameters, only 37 billion are activated during typical operations, balancing performance and resource utilization.
These innovations not only make inference more sustainable, but also demonstrate that strategic optimization can rival brute computational power.
The implications for OpenAI's business model are severe. When your $20 billion moat can be replicated for $6 million, you might need a new moat.
How Does R1 Compare to the Best Models?

R1’s performance isn’t just competing with industry leaders–it’s beating them. Here’s how it stacks up:
AIME: Crushes reasoning and comprehension tasks thanks to its reinforcement learning approach. Think of it as passing a gauntlet of tests designed by other AI models. R1 achieved a 79.8% pass rate, compared to 79.2% by OpenAI’s o1–1217.
MATH-500: Solves complex math problems better than competitors by working from first principles rather than memorized patterns. R1 scored an impressive 97.3%, slightly ahead of o1–1217’s 96.4%.
SWE-bench Verified: Excels at coding tasks—writing, debugging, and validating code with remarkable efficiency. R1 outperformed in programming tasks, showcasing its coding proficiency.
ScaleAI has confirmed what the benchmarks show: R1 matches or beats o1 across the board, especially in tasks that require deep reasoning and domain expertise.
The bottom line? DeepSeek built a model that delivers performance on par with or exceeding o1 across diverse tasks.
Distillation: Democratizing AI Access
One of the most promising aspects of DeepSeek’s approach is its successful implementation of model distillation. This technique transfers knowledge from larger models to smaller, more efficient ones (e.g. 1.5B-70B parameter versions), making top-of-the-line AI capabilities accessible to wider range of users and applications.
Here are some key insights from DeepSeek’s distillation approach with R1:
Performance Excellence: Distilled models without reinforcement learning training can outperform smaller models trained directly with reinforcement learning.
Accessibility: By reducing the size and complexity of models, distillation makes high-performance AI viable for deployment on edge devices and less advanced infrastructure.
Scalability: Enterprises and developers with limited resources can integrate advanced AI features without prohibitive costs.
By reducing inference costs, maintaining model performance, offering a higher degree of scalability and improving versatility, DeepSeek has made huge strides in bridging the gap between cutting-edge AI and practical applications.
Overall, this development strongly suggests an industry shift towards domain-specific AI. Imagine DeepSeek models fine-tuned specifically for finance, healthcare, or robotics. This targeted approach could lead to models with superior accuracy and reduced hallucinations within specific domains, since they can be trained on highly curated and relevant data.
The Open Source Advantage
The contrast between OpenAI’s increasingly closed approach and DeepSeek’s open-source strategy highlights a philosophical divide in the AI industry. For companies like OpenAI and Meta that have tried to gatekeep this AI technology to make as much money as possible, the release of R1 has caused a lot of panic in their internal teams this week.
By adopting an MIT license, DeepSeek empowers users to freely distill, modify, and commercialize its models. This approach, ironically, better fulfills OpenAI’s original mission of open sourcing AI development as a non-profit. Perhaps “ClosedAI” would be a better name for the company now.
The implications of an open-source approach:
Innovation Acceleration: Open access encourages a diverse range of contributors, fostering rapid advancements and novel applications.
Philosophical Alignment: DeepSeek’s strategy aligns more closely with the original mission of "Open"AI than the organization itself, sparking discussions about ethics and accessibility in AI development.
Economic Equality: Small businesses, academic researchers, and underfunded developers gain equal opportunities to leverage cutting-edge AI technology.
This philosophy challenges the industry’s current trajectory, pushing for a more collaborative and inclusive ecosystem.
Cost and Accessibility
The economic implications of DeepSeek’s methodology are profound, presenting a stark contrast to the current paradigm of AI development.
A few metrics for you to think about:
Development Costs: DeepSeek’s R1 model was developed (allegedly!) for approximately $6 million—a fraction of the billions spent by industry giants.
API Pricing: Costs of $0.55/$2.19 per million input/output tokens significantly undercut competitors like o1, which charge $15/$60.
Energy Efficiency: DeepSeek’s models are 97% more energy-efficient than competing models (looking at you ChatGPT), reducing environmental impact and operational costs.


Innovation Under Hardware Constraints
Remarkably, DeepSeek achieved these breakthroughs with their R1 model despite facing hardware limitations due to export controls. This constraint-driven innovation led to creative solutions like:
Efficient Attention Mechanisms: Redesigned to maximize output while minimizing resource use.
Sparse Activation Patterns: Activating only the most relevant model components to reduce overhead.
Optimized Architectures: Structuring models to achieve high performance with limited hardware availability.
As we’ve learned from the last decade or so of startups, having less resources (in this case top-of-the-line GPUs) can actually be a catalyst for ingenuity. DeepSeek has shown the world that creating an AI model is no longer a capability that’s exclusively reserved for multinational American tech giants that have billions sitting around.
Looking Forward
DeepSeek’s success challenges several entrenched assumptions about AI development:
Massive computing resources are not always necessary for state-of-the-art performance.
Supervised learning is not the only pathway to building highly capable AI systems.
Open-source development can compete with and even surpass proprietary approaches.
Billion-dollar budgets are not prerequisites for impactful innovation.
As the industry begins to absorb these lessons, we may witness a shift toward more efficient, accessible, and open approaches to AI development. This transformation has the potential to:
Empower smaller players and emerging markets to contribute meaningfully to AI advancements.
Foster a more diverse and competitive ecosystem, driving innovation from unexpected sources.
Align technological progress with principles of equity and sustainability.
If you're running a business that uses AI services, your costs are about to drop dramatically. If you're building AI products, you now have a viable path to developing proprietary models without raising hundreds of millions in capital.
For the big players—OpenAI, Anthropic, and others—this is a moment that requires serious strategic reflection. Their technical advantages appear increasingly temporary, and their pricing power is likely to erode.
We’re entering an era where compute isn’t primarily used for training, it’s for creating better data. I expect to see a shift of resources from pre-training to data processing (generation, annotation, curation).
DeepSeek’s R1 model exemplifies a future where success in AI is defined not by the scale of resources but by the ingenuity of their use. This democratization of AI development has the potential to accelerate innovation and create a more inclusive, collaborative industry landscape.