

Has AI Video Generation Finally Turned the Corner?
Unpacking the technology and market dynamics fueling the latest developments in video generation models

AI video generation used to be a parlor trick: a few janky frames, some kaleidoscopic glitching, maybe a faint resemblance to the prompt if you squint hard enough. But over the last few months, it’s clear we’re in the thick of a creative arms race.
From hyper-realistic cinematic sequences to animated social content generated in seconds, video generation has gone from gimmick to viable production tool—if you know where to look.
But let’s get clear on what differentiates today’s wave of AI video models, because it’s not just about higher resolution or longer duration. It’s about how they generate video, what they’re optimized for, and who they’re trying to serve.
What’s Actually Happening Under the Hood?
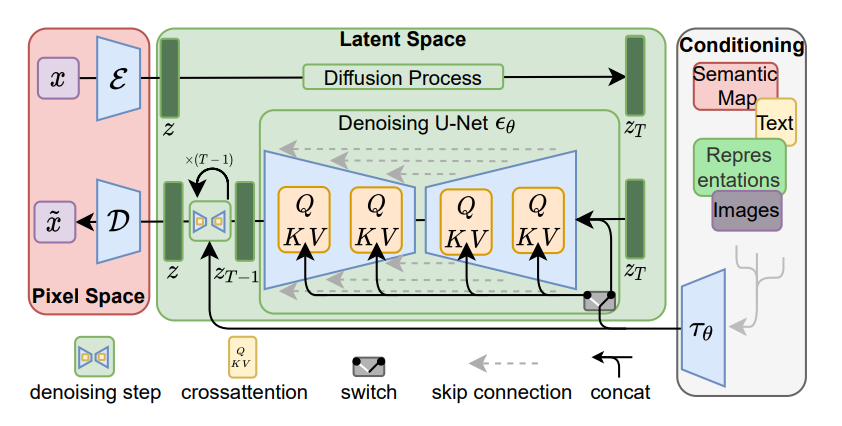
At the heart of most modern AI video generation models are techniques borrowed from image generation—just extended into the “fourth dimension”: time.
Many of the leading models use a combo of diffusion models and Transformer-based backbones. If that sounds familiar, it’s because they’re architecturally related to image models like Stable Diffusion and DALL·E—but retrofitted for spatiotemporal coherence. In practice, this means models now treat video as a set of frames with dependencies not just in space (like images) but across time.
These models generally rely on techniques like:
Latent diffusion (LDMs) to make training and inference more efficient
DiT backbones (Diffusion Transformers) with bidirectional attention across space and time
Progressive training, starting with short low-res clips and gradually extending resolution and duration
Joint training on images and video, to leverage massive high-quality image datasets for visual grounding
But where they differ—sometimes dramatically—is in how they maintain consistency, scene control, and creative flexibility.
Differentiating the Leaders
Ask anyone who’s tried early video generation models, and they’ll tell you the same story: you get a few seconds of exciting footage, and then something melts. A chair turns into a dog. A car drives into itself. Characters teleport. It’s unsettling—and not in a good way.
Several key players currently dominate the AI video generation landscape, each distinguished by unique strengths and market focuses:
Meta (Emu and MovieGen): Meta employs a factorized generation approach (Emu Video), enabling high-resolution outputs with notable temporal consistency. Their MovieGen model challenges traditional beliefs about causality and employs a hybrid tokenizer combining 2D and 1D operations, resulting in exceptional motion fidelity.
Google (Gemini Veo 2): Google differentiates itself through a cinematic realism focus, handling sophisticated prompts with capabilities like simulating depth-of-field effects and realistic physics. This makes Veo 2 ideal for premium visual content where creative accuracy is paramount.
OpenAI (Sora): Leveraging the popular latent diffusion framework and joint image-video training, Sora efficiently handles a variety of video formats from widescreen to vertical. Its emphasis on prompt rewriting and text-video alignment positions it strongly for rapid-turnaround social media content.
Sand AI (MAGI-1): This model stands apart with an autoregressive generation approach, managing high temporal consistency over extended video sequences through chunk-based generation. MAGI-1 also excels at physical realism, providing flexibility with different model sizes suited to various computational resources.
Synthesia: Great for generating videos with realistic virtual humans or avatars suitable for corporate use cases like talking-head explainers, HR training, and presentation-style videos.
Runway: Provides strong control over characters, scenes, and camera motion with a high degree of coherence and consistency for professional production-studio level content.
Who’s This Actually For?
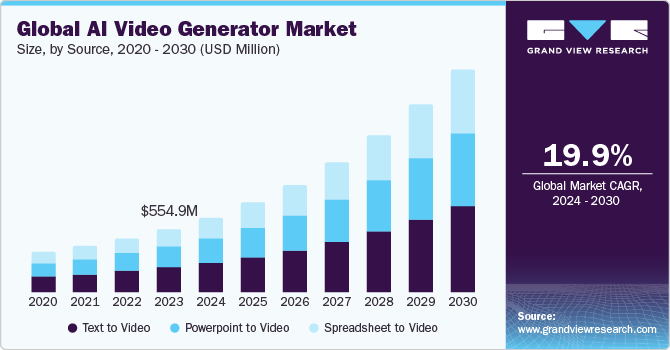
The global AI video generator market reached $554.9 million in 2023 and is projected to grow at a staggering 19.9% CAGR through 2030. This growth is being fueled by our insatiable appetite for video content (approximately 80% of online traffic is now video-driven), reflecting how decisively consumers have shifted their preferences from text to visual media.
Companies and creators across a wide range of markets are finding that these tools provide several key benefits:
Production Cost Reduction: Creating video assets without expensive shoots
Rapid Iteration: Testing multiple concepts quickly before committing to production
Personalization at Scale: Generating customized video content for different audience segments
Workflow Enhancement: Allowing creative professionals to focus on creative direction rather than technical execution
The explosion of tooling isn’t theoretical. AI video generation is already embedded in the workflows of:
Social media marketers making quick-hit reels without actors or voiceovers
E-commerce teams animating product stills into lifestyle videos
Educators and internal comms teams creating talking-head style videos for training, onboarding, and product demos
SMBs and creators turning to Pika Labs or Runway for high quality content with modest budgets
Even Adobe, Canva, and Kuaishou (Kling) are in the mix, layering these tools into existing design ecosystems. Adobe is weaving video generation into the broader Creative Cloud ecosystem (via Firefly and the Rephrase.ai acquisition). These aren't standalone models so much as generative accelerators: scene enhancement, safe-for-commercial-use assets, virtual actors.
Meanwhile, high-end studios are watching closely. Tools like Runway’s Gen-4 are starting to regenerate characters across perspectives and scenes, blurring the line between AI assistance and full-on production replacement for certain scenarios.
What’s Holding the Field Back?
A number of bottlenecks remain:
Latency Problems: Generating high-quality videos can be slow, especially for longer or higher-resolution outputs, leading to long processing times and limited video length.
Resolution constraints: Anything above 1080p remains rare, especially for long videos.
Compute demands: Generating a 20-second high-quality clip often needs multiple A100s—or hours of patience.
Generalization: Most models need very specific prompts. Ask for something weird and you’ll likely get uncanny valley or straight-up noise.
Coherence at scale: The longer the video, the harder it is to maintain object permanence, camera logic, or temporal sanity. Despite tricks like progressive training or chunking, most models still break down beyond ~20 seconds.
Ethical considerations and copyright issues: Clean, diverse, high-quality video datasets are hard to license, watermark, or scale legally.
Looking Ahead
For business leaders and creative teams, the key question isn’t whether AI video works—it’s how to strategically integrate them to enhance existing workflows rather than replacing them. The most successful implementations will likely be those that combine AI generation with human creative direction, using these models as powerful extensions of human creativity rather than replacements for it.
As computational efficiency improves, we'll likely see:
More real-time or near-real-time generation capabilities
Better integration with existing creative workflows
More specialized models targeting specific industry needs
Improved handling of specific challenges like human motion and facial animation
I don’t believe AI-generated video will replace a film crew anytime soon, but if your marketing team needs a thousand variants of a product video? Or your app wants to generate dynamic user visuals? The tech is not just possible—it’s ready.
You just need to pick the right tool for the job. And in this rapidly growing space, that choice is changing fast.