

Context Engineering for AI Agents: The New Bottleneck
In the agent era, how you shape context matters more than the size of your model

The biggest bottleneck in AI today isn’t model size.
It’s memory.
Every AI agent—no matter how powerful the underlying model—lives and dies by what fits into its context window. Plans, tool calls, errors, and observations all compete for the same limited space.
Fill it badly, and the agent slows down, drifts off course, or collapses under its own weight.
Shape it well, and the same model suddenly looks sharper, faster, and more reliable.
This discipline has a name: context engineering.
If the model is the CPU, context is RAM. And just as operating systems revolutionized computing by managing memory, context engineering is emerging as the operating system for AI agents.
It’s not about clever prompts anymore. It’s about designing how information flows, persists, and gets reused inside the loop.
Why Context Matters More for Agents Than for Chatbots
Chatbots live in a balanced world: you send a prompt, they return an answer. Input and output stay roughly proportional.
Agents operate differently.
In Manus, one of the most ambitious agent systems built to date, the average ratio of input to output tokens is about 100:1. Each action taken and each observation received is appended to context.
What grows is the log of state. What shrinks is the output—often a short structured function call.
This imbalance has real consequences:
Poorly engineered context drives latency, inflates costs, and produces brittle behavior.
Well-engineered context keeps agents fast, grounded, and reliable.
It’s the difference between an agent that drifts after ten steps and one that runs through fifty without breaking stride.
The Craft: How Engineers Shape Context
Look closely at production agents and you’ll see recurring patterns—practices that tame sprawling traces into stable loops.
1. Optimize the loop.
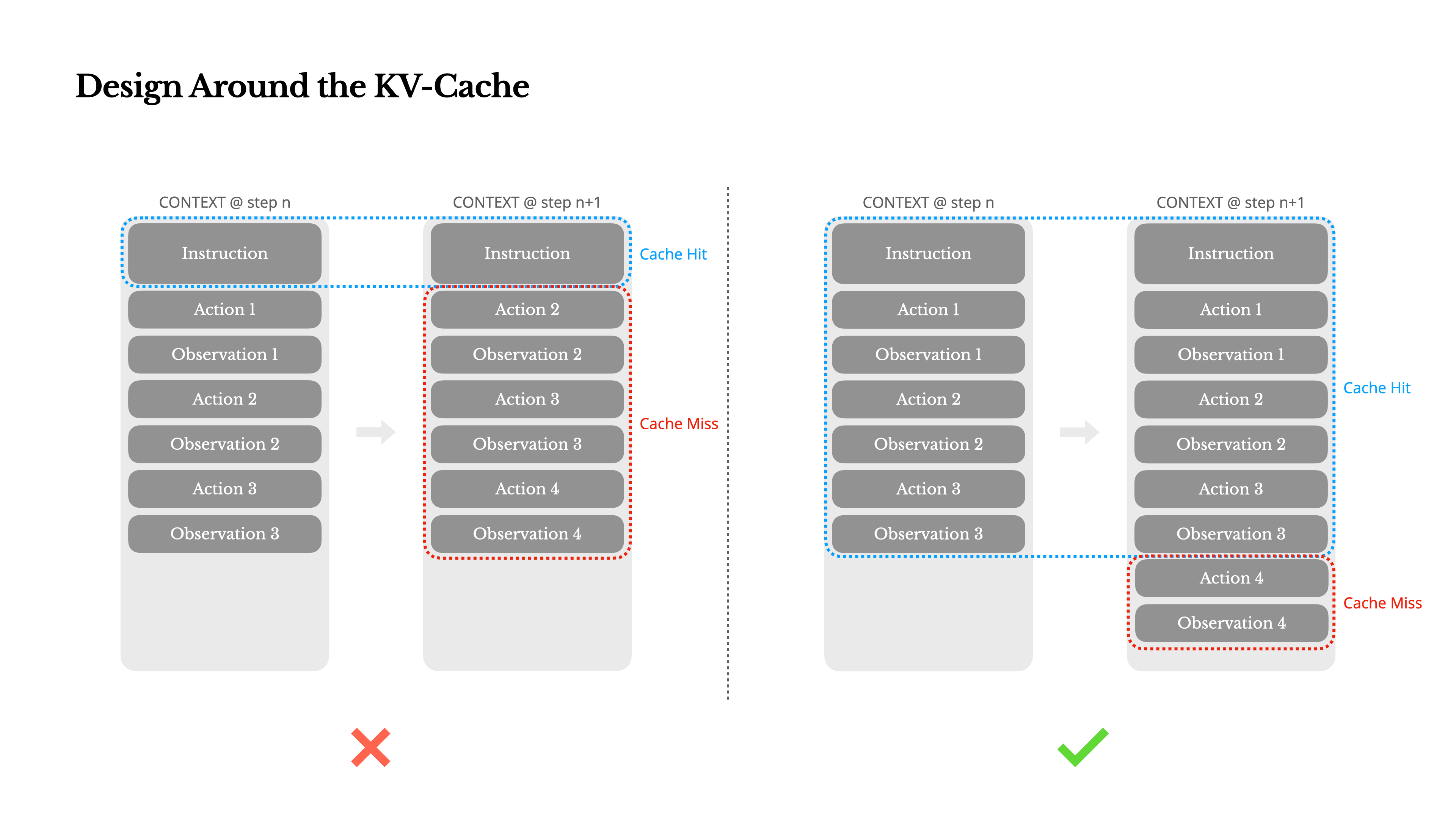
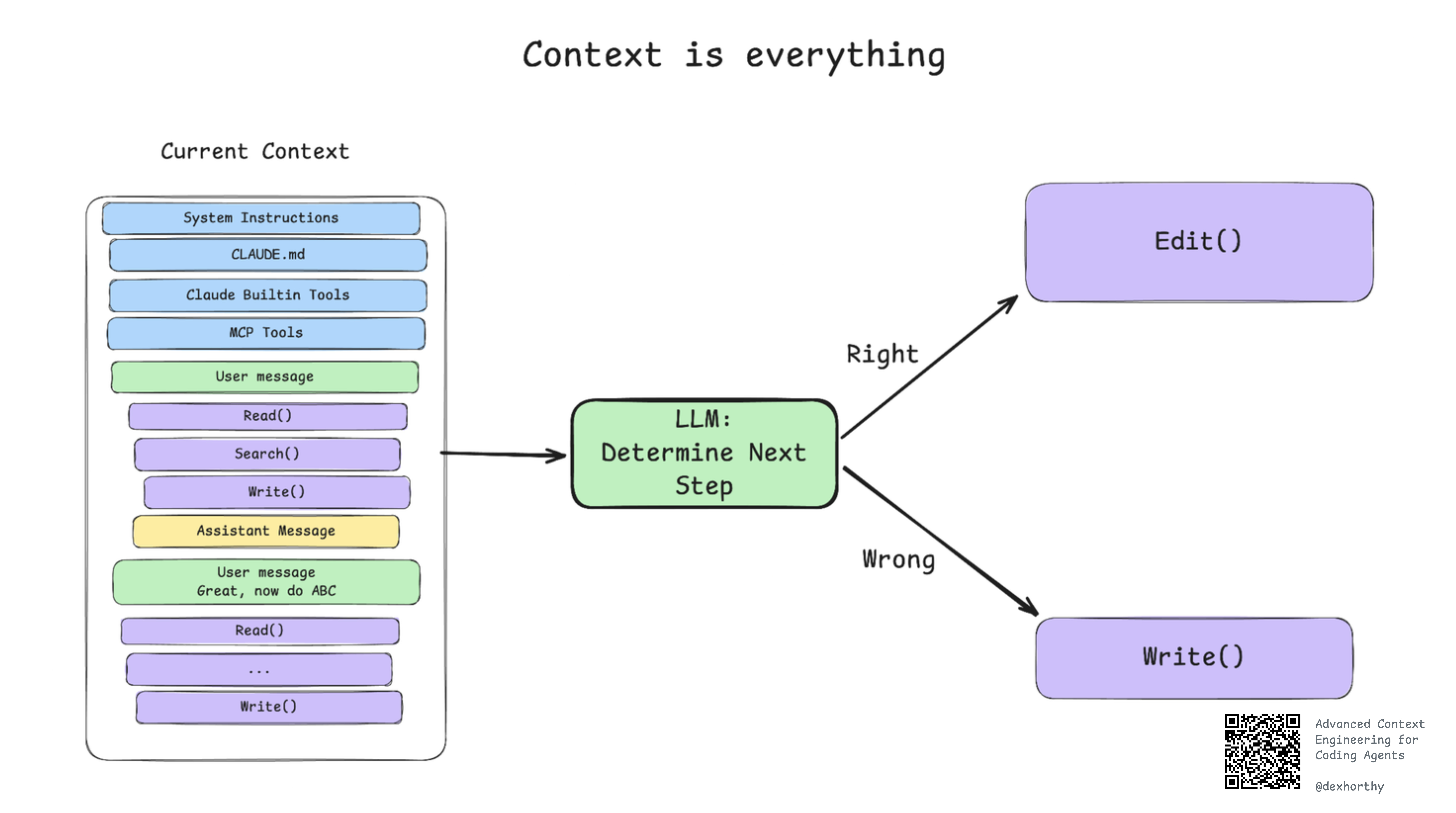
KV-cache hit rate is the single most important performance metric.
Keep system prompts stable.
Use deterministic serialization.
Append logs instead of modifying them.
These basics can mean the difference between paying three dollars per million tokens and thirty cents. Even small details—like including a timestamp in the system prompt—can wipe out cache efficiency.
2. Control the action space.
As agents accumulate tools, it’s tempting to dynamically load or unload them. That usually backfires.
Tool definitions live at the front of context, so edits invalidate the cache.
Earlier steps may reference tools no longer present, creating confusion.
Better: mask tokens during decoding. Constrain choices without reshuffling the context.
3. Externalize memory.
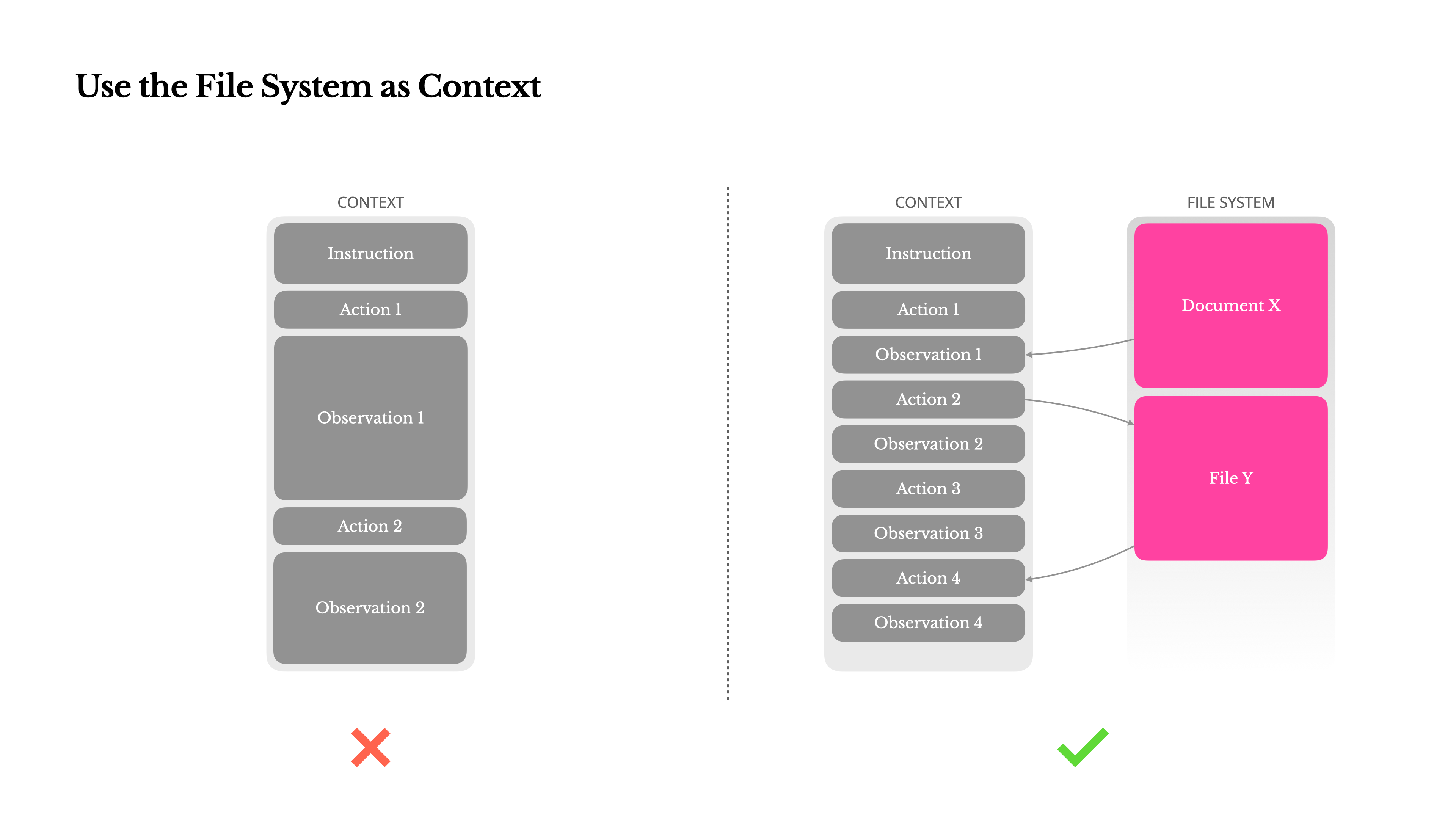
Even million-token windows fill fast with PDFs, codebases, or web pages. Compress too aggressively and you lose critical details.
We can solve this by treating the file system as context.
Keep the URL or path.
Reload details on demand.
This approach makes context management restorable rather than destructive.
4. Manipulate attention.
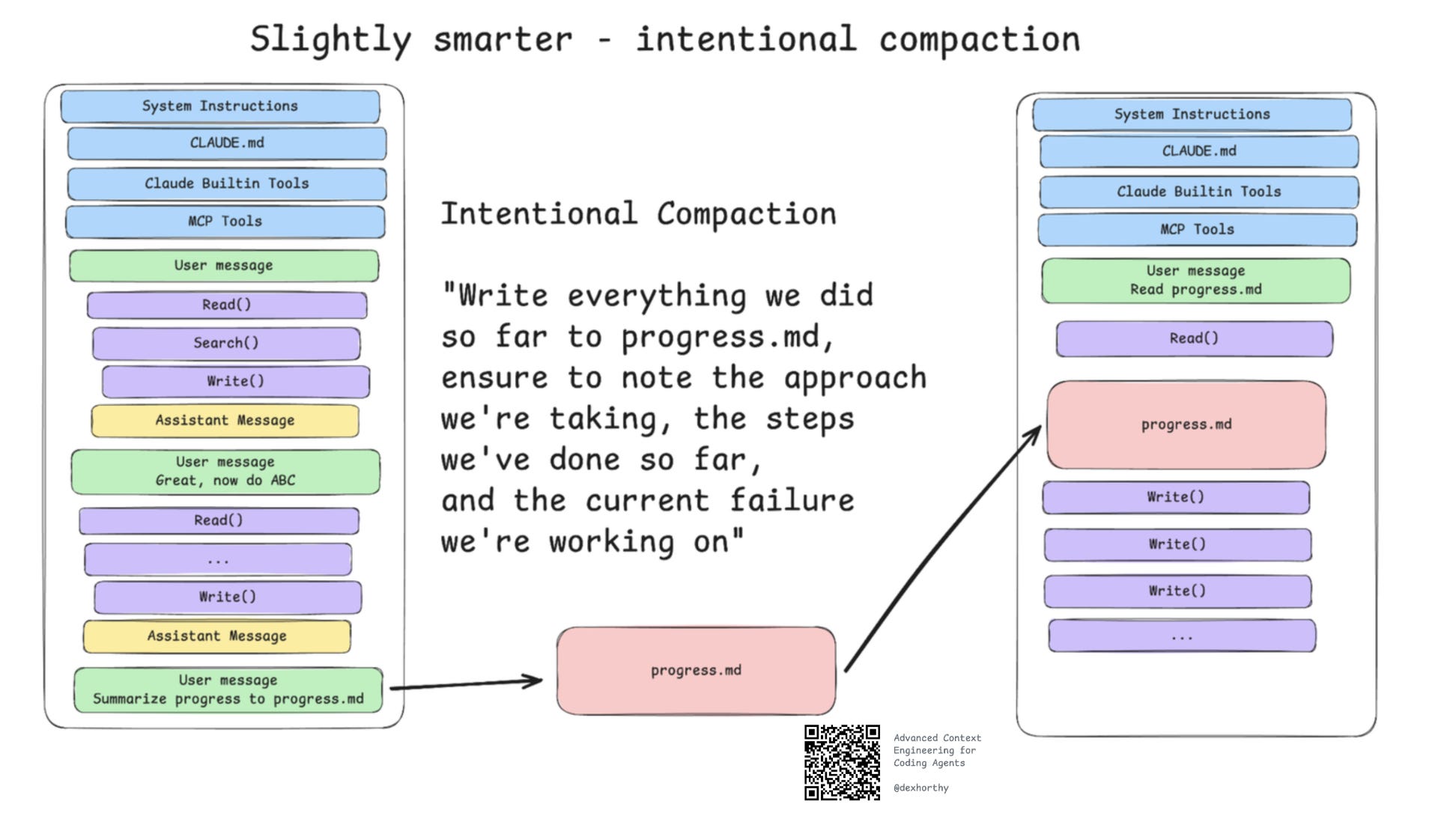
Using a process known as intentional compaction, we can manipulate an agents attention by creating a progress.md file and updating it step by step. By rewriting the plan and appending it to the end of the context, we can keep global goals in short-term attention—avoiding “lost in the middle” drift.
5. Preserve errors.

Developers instinctively sanitize traces, but errors are valuable signals. Leaving failed actions in context helps models implicitly adjust and avoid repeating mistakes.
6. Break the pattern.
Few-shot prompting can trap agents in brittle mimicry. Agents can sometimes fall into repetitive loops when reviewing something like resumes. Introducing small variations—different serialization formats, alternate phrasing—can keep them from overgeneralizing.
Scaling the Craft into Real Systems
Micro-level practices only go so far. Scaling agents requires macro-level structure. That’s where compaction comes in.
Many teams now use research → plan → implement cycles, with compaction baked into the workflow.
Each phase produces structured artifacts (summaries, plans, logs).
Utilization stays in the 40–60% sweet spot.
Subagents handle exploration and summarization so the main loop doesn’t drown in detail.
Infrastructure reinforces these habits:
Retrieval has evolved to hybrid dense + sparse with reranking.
Memory is two-tiered: short-term in context, long-term in external stores.
Tool catalogs are typed schemas with constraints, enforced through logits instead of edits.
What hasn’t worked—at least not yet—is multi-agent parallelism. Splitting tasks across agents looks promising but context sharing is too shallow. Subagents misinterpret subtasks, leaving the final agent to reconcile inconsistencies.
For now, the most reliable systems remain single-threaded agents with disciplined context management.
The Industry Direction
Big players are converging on context as the runtime:
OpenAI: structured outputs and evals to shape and verify context.
Anthropic: cheaper long context, constrained tool use, “computer use.”
Google: Gemini embedded into Chrome, turning browser state into context.
Frameworks are racing to keep up:
LangGraph for stateful flows.
DSPy for compiled context pipelines.
LlamaIndex for retrieval and memory.
Governance is catching up too:
OWASP warns about context injection.
NIST frames context as a security boundary.
The message is clear: models may dominate the headlines, but context is where engineering actually happens.
Emerging Best Practices
A playbook is starting to form:
Engineer layered recipes: system rules → state → facts → tool schemas → output contract.
Compact by default, not as a last resort.
Preserve errors and variation rather than sanitizing traces.
Treat context as an artifact: version it, test it, evaluate before shipping.
Harden context boundaries: allow-lists, redaction, sandboxing.
Context as the Real Engine
It’s tempting to think bigger models will solve everything.
But frontier lessons—from KV-cache discipline to file-based memory to recitation and error preservation—show otherwise. Models keep getting smarter. Yet the real bottleneck isn’t intelligence. It’s context.
And that’s the point: the future of AI agents won’t be decided by parameter counts. It will be decided by how well we engineer the context they run on.