

Benchmarks Are Useful, Misleading, and Totally Missing the Point
Don't get lost in the weeds on what the benchmarks say is the "best" model

The AI world is obsessed with benchmarks. They offer the illusion of objectivity, precision, and meaningful comparison across wildly different entities. The results? Glorious graphs, leaderboards, and breathless tweets about how one model is better than another model or maybe the latest model is now better at AP Bio than your cousin who actually took the class.
But here’s the thing: most benchmarks are solving the wrong problem. I wouldn’t say they’re useless, but they don’t paint the full picture. Or rather, they are solving the right problem in a way that doesn't matter to anyone outside the benchmark circuit. They are good at telling you how a model performs on a benchmark, and that’s... pretty much it.
Before we go full skeptic, let’s back up and cover the basics.
What Are Benchmarks Supposed to Do?

AI benchmarks are standardized tests designed to evaluate the performance of artificial intelligence models on specific tasks.
Think of them as SATs for LLMs: you get a score, you make a leaderboard, you quantify model performance compared to other models.
They usually come in the form of multiple-choice questions, coding tasks, or reasoning problems across domains like math, language, science, or programming. Some are zero-shot, where the model gets no training examples. Others are few-shot, where it gets a handful. Either way, you're testing what the model learned from pretraining and whether it can apply that knowledge.
Benchmarks like MMLU, ARC-AGI, or Codeforces attempt to answer the question, "How good is this model at X?" where X ranges from solving grade school math problems to handling GitHub tickets.
In theory, AI benchmarks tell us two things:
How smart is this model?
What is this model useful for?
Unfortunately, very few of them do either well. Intelligence is not a scalar quantity, and usefulness depends on your actual business constraints, not whether your model gets a 0.1% boost on GSM8K. And over time, as models and researchers aim to squeeze out every last point, the benchmark stops being a meaningful signal and becomes just another leaderboard game.
A Brief Tour of the Common Benchmarks
There’s a reason there are so many AI benchmarks—and why new ones keep popping up. Each benchmark targets a different dimension of intelligence: symbolic reasoning, factual recall, scientific understanding, code generation, multi-step dialogue, and more.
The proliferation of benchmarks isn’t a bug; it’s a feature. It reflects the fact that “intelligence” is multi-dimensional, and no single test can capture it all. But it also means that anyone chasing the top of a leaderboard is always playing on shifting ground.
As models improve, they begin to saturate existing benchmarks, scoring near-perfect results not because they’ve achieved AGI, but because they’ve overfitted to the test set. When a model aces HumanEval or MMLU, researchers don’t declare victory—they invent a new, harder test.
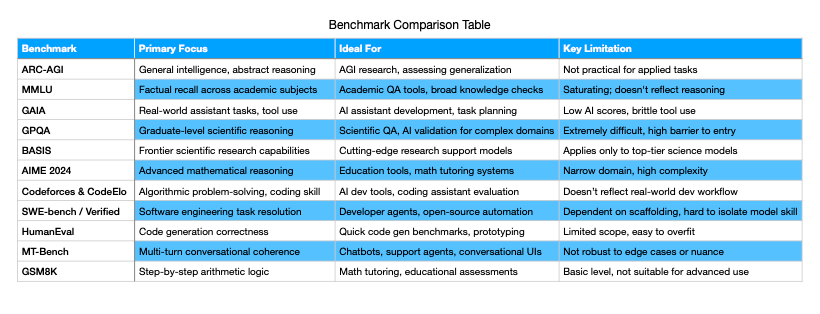
ARC-AGI: This benchmark evaluates general intelligence by testing models on tasks that are trivial for humans but unexpectedly challenging for AI. These include abstract reasoning, symbolic manipulation, and rule composition tasks that require generalization from sparse data. ARC-AGI is designed to spotlight the human-AI gap in fluid intelligence rather than measure narrow domain proficiency.
MMLU: The Massive Multitask Language Understanding benchmark assesses factual recall and problem-solving abilities across 57 diverse subjects, including mathematics, law, medicine, and history. Evaluated in zero- and few-shot settings, MMLU is particularly effective at exposing blind spots in models' pretrained knowledge and their ability to respond accurately without additional training.
GAIA: GAIA is focused on evaluating real-world assistant capabilities, combining tasks that require reasoning, multimodal understanding, tool use, and web interaction. Although these tasks are conceptually simple for humans, they expose severe limitations in current AI systems. Human performance averages 92%, whereas even advanced models with plugins score dramatically lower, underscoring a critical robustness gap.
GPQA: The Graduate-Level Google-Proof Q&A benchmark measures a model's ability to answer high-difficulty scientific questions without relying on superficial web search strategies. With questions authored by PhDs in biology, physics, and chemistry, GPQA emphasizes deep comprehension and scientific reasoning, offering a reliable proxy for expert-level knowledge application.
BASIS: An extension of GPQA, BASIS pushes AI models into the realm of frontier scientific inquiry. This benchmark targets research-grade capabilities in reasoning and hypothesis formulation. It's designed for models aspiring to contribute meaningfully to scientific progress, providing a high bar for evaluating models against expert-level expectations.
AIME 2024: The American International Mathematical Examination (AIME) benchmark is a dataset composed of problems from the 2024 AIME exam. It evaluates models' abilities to perform multi-step logical reasoning, apply abstract mathematical principles, and demonstrate rigorous problem-solving across domains like algebra, combinatorics, and number theory.
Codeforces & CodeElo: These benchmarks test algorithmic reasoning and programming skill in a real-world competitive setting. Models interpret the problem, code up a solution and then a bot is used to submit the solution for evaluation. This setup closely mirrors human evaluation and offers a granular view of a model’s practical coding ability against a competition style evaluation rubric.
SWE-bench / SWE-bench Verified: Focused on real-world software engineering tasks, SWE-bench asks whether AI systems can resolve GitHub issues using a full development environment. The benchmark tests agent-level performance by evaluating the model’s ability to modify code, run tests, and iterate intelligently. The Verified subset improves data quality by filtering ambiguous or infeasible tasks.
HumanEval: A widely adopted code generation benchmark that evaluates whether a model can produce functionally correct code based on a prompt and pass a suite of unit tests. It is useful for quick iteration in code modeling but is increasingly saturated, making it a less informative differentiator at the frontier.
MT-Bench: Designed to assess multi-turn conversational ability, MT-Bench evaluates how well large language models maintain context, follow instructions, and reason coherently across several dialogue steps. Scoring is now largely automated using strong LLMs as judges, which enables scalable and consistent evaluation of dialog quality.
GSM8K: This benchmark focuses on elementary-level math word problems, measuring a model's capacity for step-by-step arithmetic reasoning. Though the problems are conceptually simple, they effectively reveal issues with logical consistency and intermediate reasoning in language models.
The Benchmark Saturation Problem

By late 2024, most benchmarks started saturating. Models weren’t just passing them, they were acing them. That doesn’t mean models stopped improving. It means the tests stopped measuring. The fundamental issue is that AI progress has outpaced our ability to create lasting measurement tools.
Here’s what happens:
A benchmark is published.
Labs compete to optimize for it.
Models get fine-tuned, scaffolded, or chain-of-thought prompted into submission.
Scores improve.
Real-world usefulness? Maybe.
It’s the AI version of teaching to the test.
Benchmarks look great on paper. They give the appearance of scientific rigor and allow you to say "DeepSeek v3 outperforms 4o on MMLU by 3.3 points." It’s great for splashy tweets and attention-grabbing media articles. But in the real world, they fall short in three big ways:
They Overfit Fast: Once a benchmark is published, everyone optimizes for it. Models get fine-tuned, prompt-engineered, or scaffolded to death. Eventually, they memorize the test. Result: the benchmark becomes meaningless for forward progress.
They Ignore Cost: As OpenAI's Noam Brown put it, intelligence per dollar is the real game. A model that scores 95% on GPQA while running 5x slower and costing 100x more tokens isn’t winning. It’s just expensive.
They Miss the Product Question: Your model scoring top-10 on CodeElo is great. But can it write tests, fix bugs, and merge the PR unassisted? That’s a different question—and one most benchmarks don’t answer.
Benchmarks are useful baselines, not definitive measures of which model is "best." Performance ultimately depends on your specific requirements and implementation.
What to Do Instead
If you're building AI applications, understanding these benchmarks helps you choose the right model for your needs. But more importantly, recognize that benchmark performance is just a starting point. If you're running a company, what you really need are:
Use-case-specific evaluations
Real-world A/B tests
Cost/performance tradeoff curves
Failure mode audits
ROI models that map benchmark deltas to business impact
In other words: your own benchmarks.
So, What Should You Do With Benchmarks?
Use them like blood pressure readings. Good to have. Not the full picture. As a business leader or developer working with AI, your focus should shift accordingly - from "which model scores highest on benchmark X" to "which model delivers the most value per dollar for my specific use case."
The most technically impressive model on paper may be overkill for your specific needs, consuming unnecessary resources and budget. A mid-tier model with carefully designed scaffolding—the prompts, tools, and workflows surrounding it—might deliver 95% of the value at 20% of the cost.
What matters is whether your model:
Helps your customers do something faster
Costs less than a human doing the same thing
Fails in ways you can tolerate or mitigate
Again, I have to stress that the best benchmark is your own.
The benchmark chase will continue, but with diminishing returns as metrics. The real action has moved to practical applications and novel capabilities that don't fit neatly into existing test frameworks.
In the end, the most important benchmark isn't found in academic papers or leaderboards. It's found in whether these systems genuinely improve our lives, businesses, and society—a test far harder to quantify, but infinitely more significant.